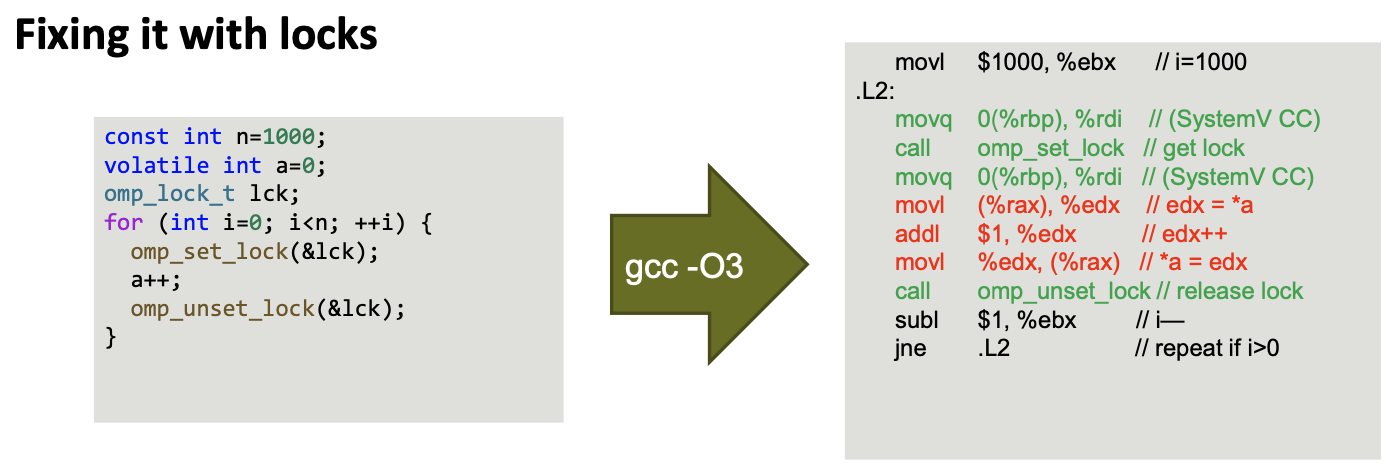
Locks
Explanation from Harvard CS Course
Control access to a critical region
- Memory accesses of all processes happen in program order (a partial order, many interleavings)
- An execution history defines a total order of memory accesses
- Some subsets of memory accesses (issued by the same process) need to happen atomically (thread A’s memory accesses may not be interleaved with other thread’s accesses)
- To achieve linearizability!
- We need to restrict the valid executions
- → Requires synchronization of some sort
- Many possible techniques (e.g., TM, CAS, T&S, …)
- We first discuss locks which have wait semantics
What must the functions lock and unlock guarantee?
- prevent two threads from simultaneously entering CR
- i.e., accesses to CR must be mutually exclusive!
- ensure consistent memory
- i.e., stores must be globally visible before new lock is granted!
Lock Overview
Lock/unlock or acquire/release
- Lock/acquire: before entering CR
- Unlock/release: after leaving CR
Semantics:
- Lock/unlock pairs must match
- Between lock/unlock, a thread holds the lock
Desired Lock Properties
- Mutual exclusion
- Only one thread is in the critical region
- Consistency
- Memory operations are visible when critical region is left
- Progress
- If any thread a is not in the critical region, it cannot prevent another thread b from entering
- Starvation-freedom (implies deadlock-freedom)
- If a thread is requesting access to a critical region, then it will eventually be granted access
- Fairness
- A thread a requested access to a critical region before thread b. Was it also granted access to this region before b?
- Performance
- Scaling to large numbers of contending threads
Hardware atomic operations
- Test&Set
- Write const to memory while returning the old value
- Atomic swap
- Atomically exchange memory and register
- Fetch&Op
- Get value and apply operation to memory location
- Compare&Swap
- Compare two values and swap memory with register if equal
- Load-linked/Store-Conditional LL/SC (or load-acquire (LDA) store-release (STL) on ARM)
- Loads value from memory,
- allows operations,
- commits only if no other updates committed
- →mini-TM
- Intel TSX (transactional synchronization)
“consensus number” C
if a primitive can be used to solve the “consensus problem” in a finite number of steps (even if threads stop)
- atomic registers have C=1 (thus locks have C=1!)
- TAS, Swap, Fetch&Op have C=2
- CAS, LL/SC, TM have C=∞
Test-and-Set Locks
Test-and-Set semantics
- Memoize old value
- Set fixed value TASval (true)
- Return old value After execution:
- Post-condition is a fixed (constant) value!
1
2
3
4
5
bool TestAndSet (bool *flag) {
bool old = *flag;
*flag = true;
return old;
} // all atomic!
On x86, the XCHG instruction is used to implement TAS
- x86 lock is implicit in
xchg! Cacheline is read and written - Ends up in modified state, invalidates other copies
- Cacheline is “thrown” around uselessly
- High load on memory subsystem
- x86 lock is essentially a full memory barrier
Test-and-Test-and-Set (TATAS) Locks
Spinning in TAS is not a good idea Spin on cache line in shared state
- All threads at the same time, no cache coherency/memory traffic
Danger!
- Efficient but use with great care!
- Generalizations are very dangerous
Do TATAS locks still have contention?
- When lock is released, k threads fight for cache line ownership
- One gets the lock, all get the CL exclusively (in M state, sequentially!)
- What would be a good solution?
- think “collision avoidance”
TAS Lock with Exponential Backoff
Exponential backoff eliminates contention statistically
- Locks granted in unpredictable order
- Starvation possible but unlikely
 How can we make it even less likely?
How can we make it even less likely? 
Maximum waiting time makes it less likely
TAS locks issues
- Cache coherency traffic (contending on same location with expensive atomics) – or –
- Critical section underutilization (waiting for backoff times will delay entry to CR)
Fixes?
Queue locks – Threads enqueue
- Learn from predecessor if it’s my turn
- Each threads spins at a different location
- FIFO fairness
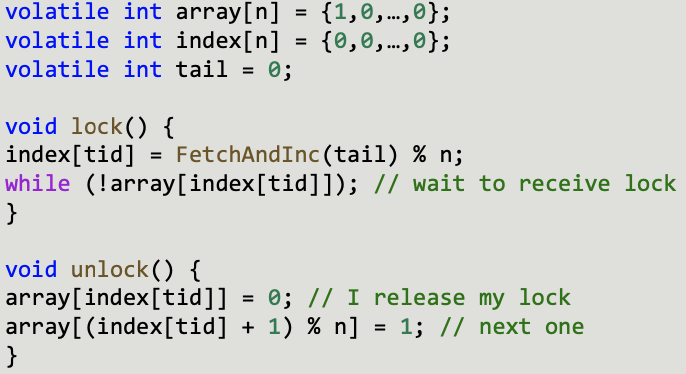
Array Queue Lock
- Array to implement queue
- Tail-pointer shows next free queue position
- Each thread spins on own location (use CL padding!)
index[]array can be put in TLS
What’s wrong?
- Synchronizing M objects requires Θ(NM) storage
CLH Lock (1993)
List-based (same queue principle)
- 2N+3M words
- N threads, M locks
- Requires thread-local qnode pointer
- Can be hidden!

Qnode objects represent thread state!
- succ_blocked == 1 if waiting or acquired lock
- succ_blocked == 0 if released lock
List is implicit!
- One node per thread
- Spin location changes → NUMA issues (in cacheless systems)
MCS Lock (1991)
Make queue explicit
- Acquire lock by appending to queue
- Spin on own node until locked is reset
Similar advantages as CLH but
- Only 2N + M words
- Spinning position is fixed! Benefits cache-less NUMA
What are the issues?
- Releasing lock spins
- More atomics!


Reader-Writer Locks
Allows multiple concurrent reads
- Multiple reader locks concurrently in CR
- Guarantees mutual exclusion between writer and writer locks and reader and writer locks
Syntax:
read_(un)lock()write_(un)lock() Seems efficient!?
Seems efficient!?- Is it? What’s wrong?
- Polling CAS! Is it fair?
- Readers are preferred!
- Can always delay writers (again and again and again)
Fighting CPU waste: Condition Variables
Allow threads to yield CPU and leave the OS run queue
Other threads can get them back on the queue!
cond_wait(cond, lock)– yield and go to sleepcond_signal(cond)– wake up sleeping threads- Wait and signal are OS calls
- Often expensive, which one is more expensive?
- Wait, because it has to perform a full context switch
When to Spin and When to Block?
Spinning consumes CPU cycles but is cheap
- “Steals” CPU from other threads
Blocking has high one-time cost and is then free
- Often hundreds of cycles (trap, save TCB …)
- Wakeup is also expensive (latency)
- Also cache-pollution
Strategy:
- Poll for a while and then block
But what is a “while”?
Optimal time depends on the future
- When will the active thread leave the CR?
- Can compute optimal offline schedule
- Q: What is the optimal offline schedule (assuming we know the future, i.e., when the lock will become available)?
- Actual problem is an online problem
Competitive algorithms
- An algorithm is c-competitive if for a sequence of actions x and a constant a holds:
- $C(x) ≤ c\cdot C_{opt}(x) + a$
- What would a good spinning algorithm look like and what is the competitiveness?
Competitive Spinning
If T is the overhead to process a wait, then a locking algorithm that spins for time T before it blocks is 2-competitive!
If randomized algorithms are used, then $e/(e-1)$-competitiveness $(~1.58)$ can be achieved
Coarse vs. Fine Grained Locks
Where do we put locks in a program? And how many locks should there be? These questions have motivated the designs of several different locks and synchronization mechanisms.
The most basic choice is between having few coarse-grained locks and many fine-grained locks. To summarize the advantages and disadvantages:
Few coarse-grained locks (1 lock protects many resources)
- Correctness is easier (with only one lock, there’s less chance of grabbing the wrong lock, and less risk of deadlock)
- Performance is lower (not much concurrency)
Many fine-grained locks (1 lock protects a small number of resources)
- Good concurrency/parallelism = good performance
- Correctness is harder (it’s easier to make a mistake and forget to grab the lock required to access a resource)
- Higher overhead from having many locks
To achieve greater concurrency – and often better performance – we can move to finer-grained locks. Rather than protecting all system resources, each fine-grained lock will protect a single resource, or a small number of them. Rather than holding a lock for a long time (as above, where a process holds the whole-system lock for as long as it runs), each process will hold this lock for as little time as possible while still providing protection. In this example, we might have a lock that protects buffer accesses; each process grabs the lock, writes a single character into the buffer, releases the lock, and repeats.