Memory Models
Memory Models
We need to define what it means to “read a location” and “to write a location” and the respective ordering!
- What values should be seen by a processor?
First thought: extend the abstractions seen by a sequential processor:
- Compiler and hardware maintain data and control dependencies at all levels:
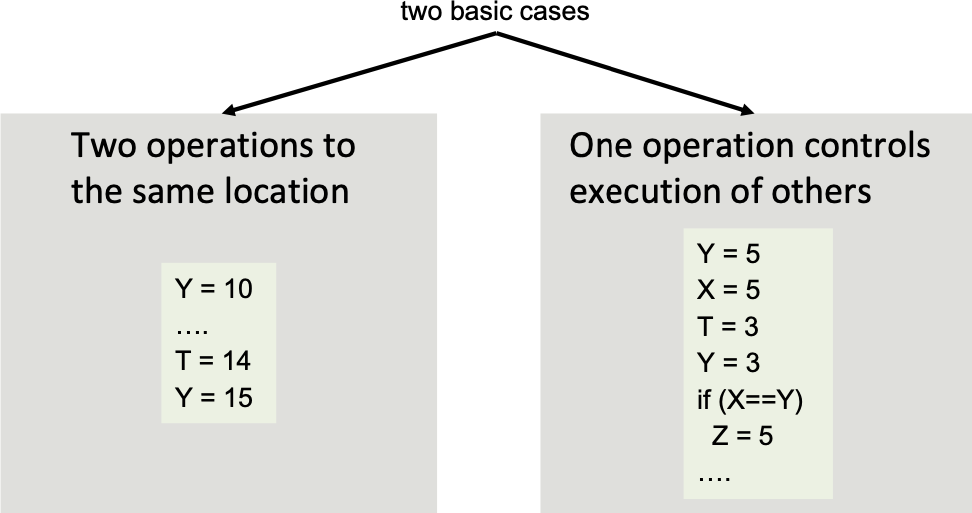
A read returns the value last written to the same location. “Last” is determined by program order!
| Program order | Visibility order |
|---|---|
| Deals with a single processor | Deals with operations on all processors |
| Per-processor order of memory accesses, determined by program’s control flow | Order of memory accesses observed by one or more processors |
| Often represented as trace (may depend on specific input arguments) |
Sequential Consistency
Extension of sequential processor model
The execution happens as if
- The operations of all processes were executed in some sequential order (atomicity requirement), and
- The operations of each individual processor appear in this sequence in the order specified by the program (program order requirement)
It applies to all layers!
- Disallows many compiler optimizations (e.g., reordering of any memory instruction)
- Disallows many hardware optimizations (e.g., store buffers, non-blocking reads, invalidation buffers)
It provides:
- globally consistent view of memory operations (atomicity)
- strict ordering in program order

Original definition: “The result of any execution is the same as if the operations of all the processes were executed in some sequential order and the operations of each individual process appear in this sequence in the order specified by its program” (Lamport, 1979)
- A load L from memory location A issued by processor Pi obtains the value of the previous store to A by Pi, unless another processor has to stored a value to A in between
- A load L from memory location A obtains the value of a store S to A by another processor Pk if S and L are “sufficiently separated in time” and if no other store occurred between S and L
- Stores to the same location are serialized (defined as in (2))
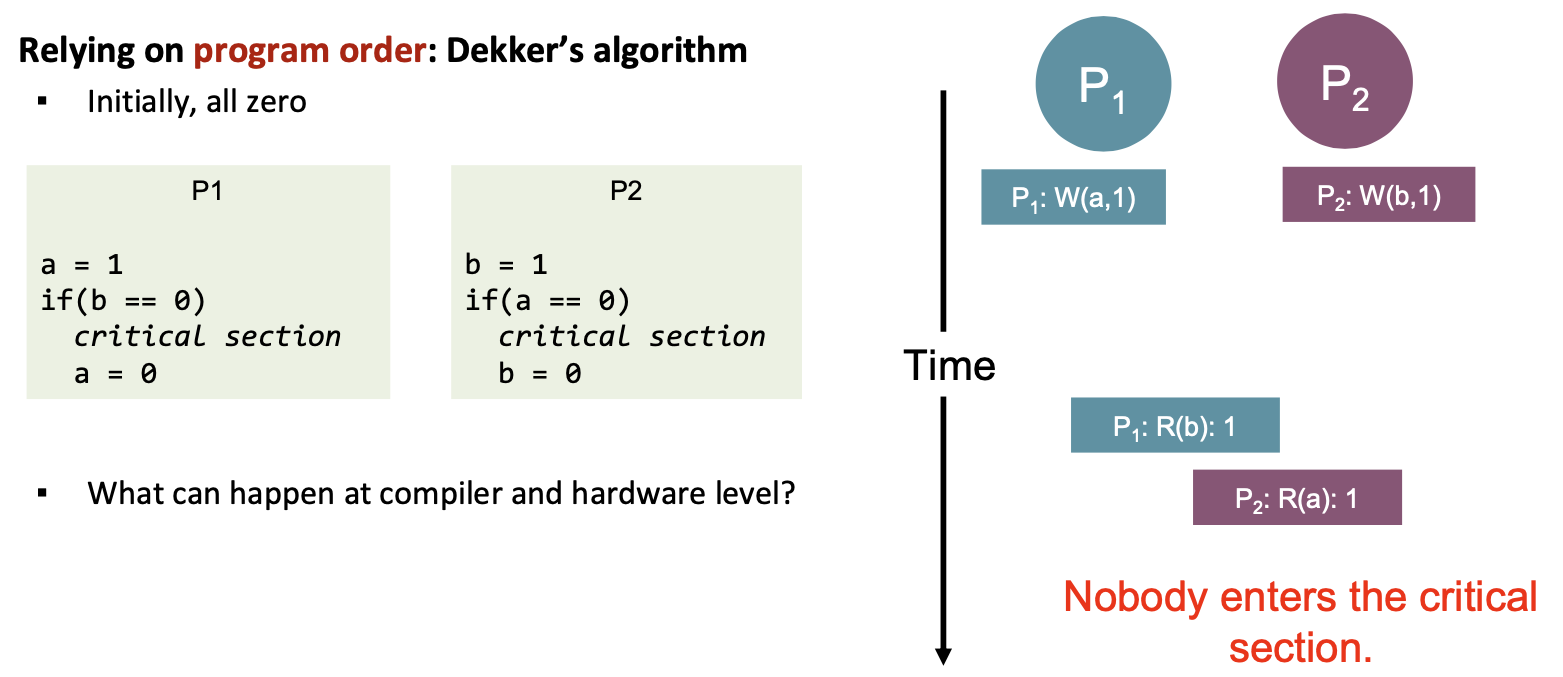
Without SC, both writes may have gone to a write buffer, in which case both Ps would read 0 and enter the critical section together.
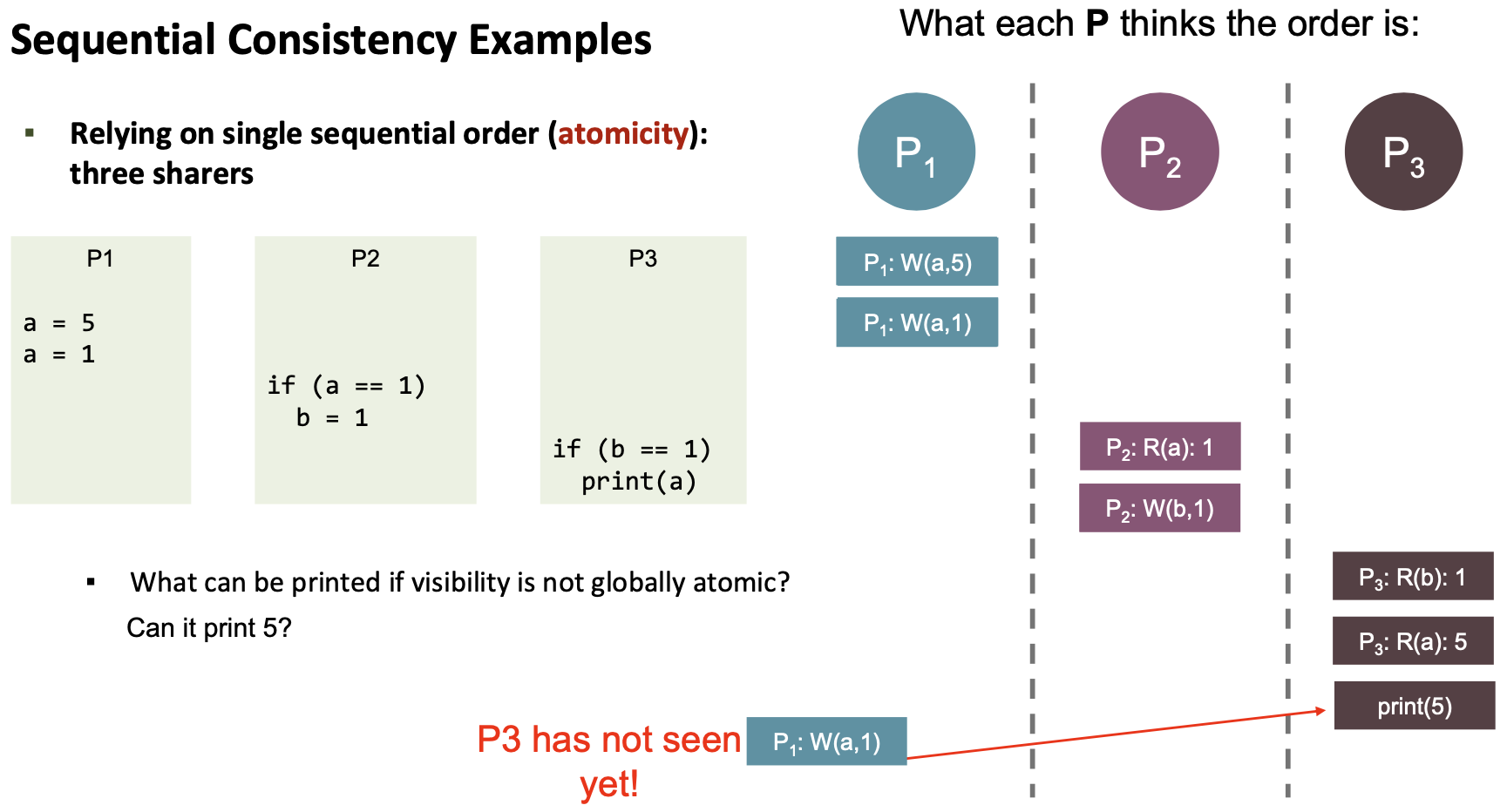
Partial and Total Order
Partial order on memory requests A → B:
- If $P_i$ issues two requests A and B and A is issued before B in program order, then A → B (on issuing process)
- A and B are issued to the same variable, and A is issued first, then A → B (on all processors)
- These partial orders can be interleaved, define a total order
- Many total orders are sequentially consistent!

Only the first one is sequentially consistent.
Write buffer
Write buffers absorb writes faster than the next cache → prevents stalls.
Write buffers aggregate writes to the same cache line → reduces cache traffic 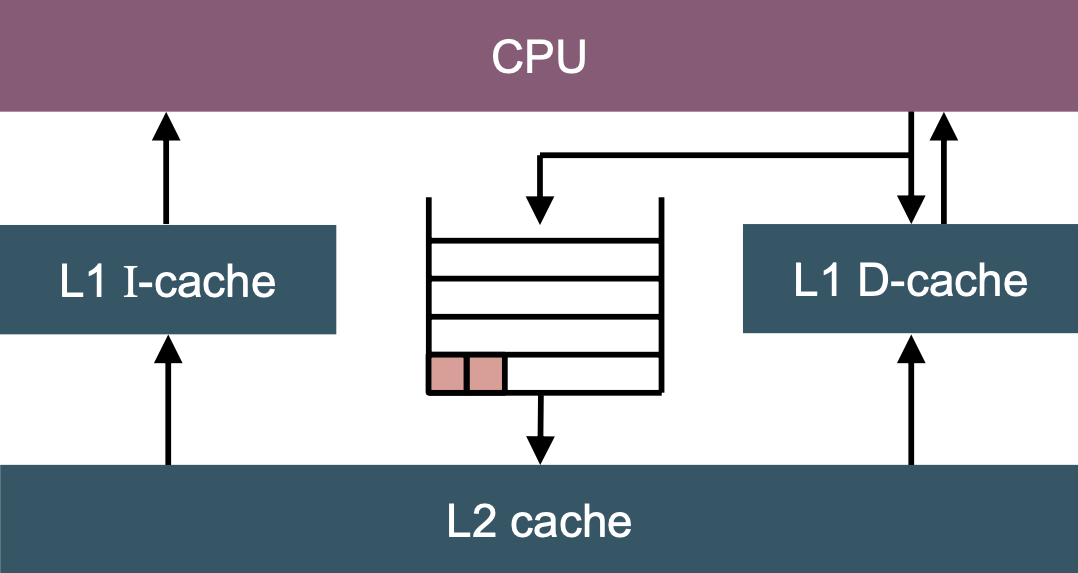
Reads can bypass previous writes for faster completion
- If read and write access different locations
- No order between write and following read (W → R)
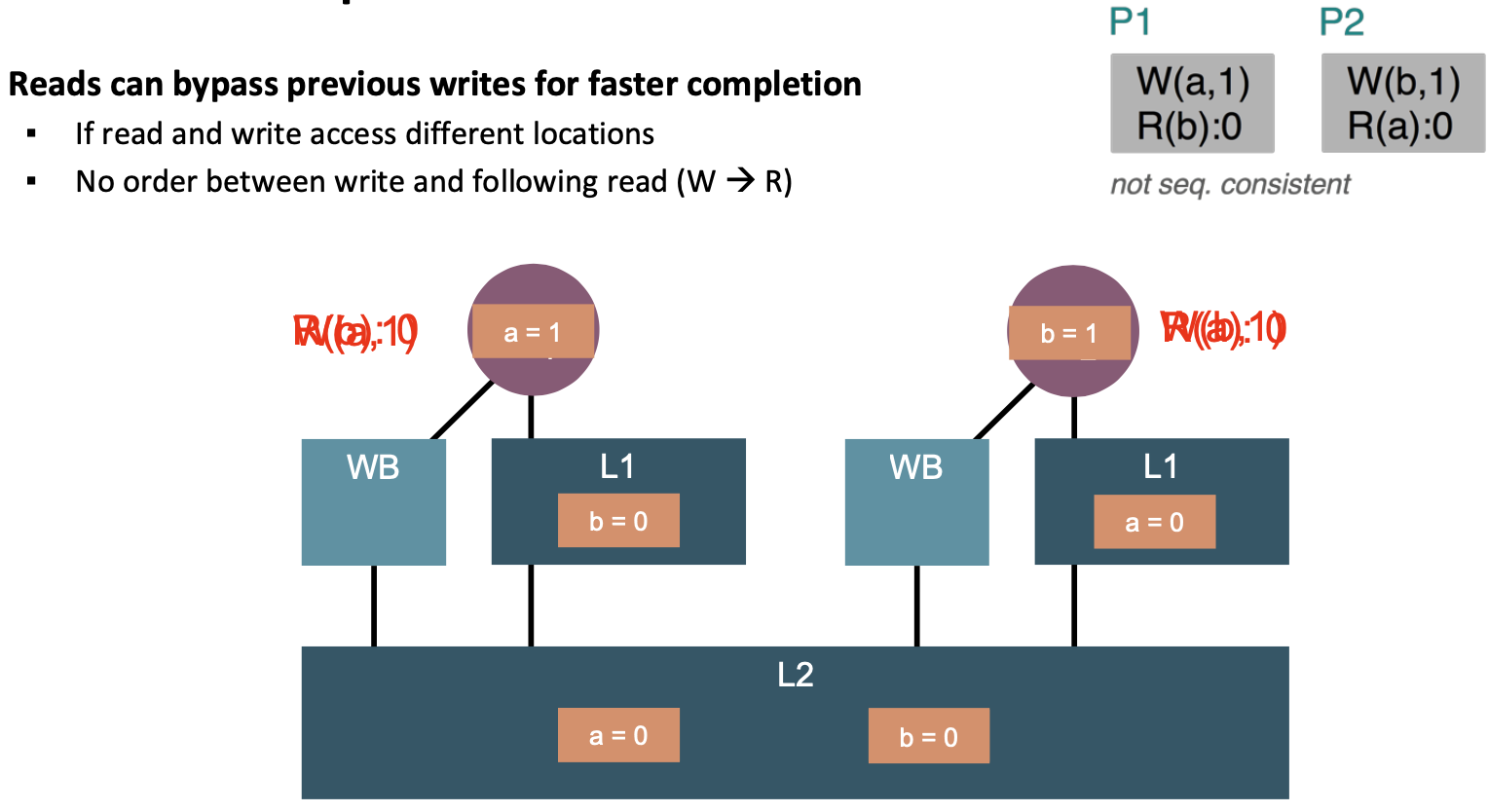
Cache coherence: a mechanism that propagates writes to other processors/caches if needed.
Recap:
- Writes are eventually visible to all processors
- Writes to the same location are observed in (one) order
Memory models:
- define the bounds on when the value is propagated to other processors
- e.g., sequential consistency requires all reads and writes to be ordered in program order
Relaxed consistency (varying terminology)
- Processor consistency (aka. TSO)
- Relaxes W→ R
- Partial write (store) order (aka. PSO)
- Relaxes W→ R, W→ W
- Weak consistency and release consistency (aka. RMO)
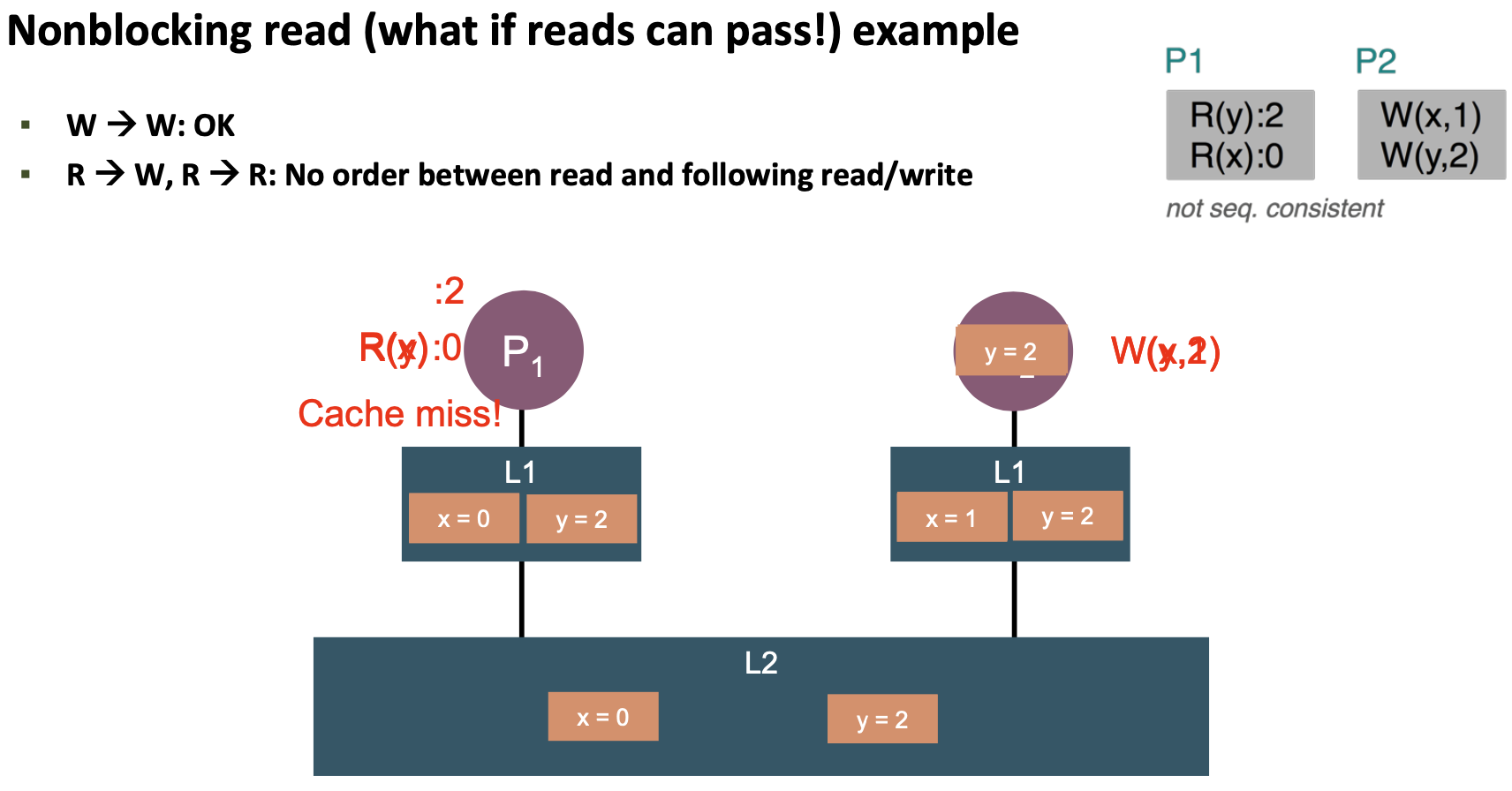
- Relaxes R→ R, R→ W, W→ R, W→ W
- Other combinations/variants possible
The 8 x86 Principles
| # | Principle | Description | Answers |
|---|---|---|---|
| 1 | “Reads are not reordered with other reads.” (R→R) | ||
| 2 | “Writes are not reordered with other writes.” (W→W) | 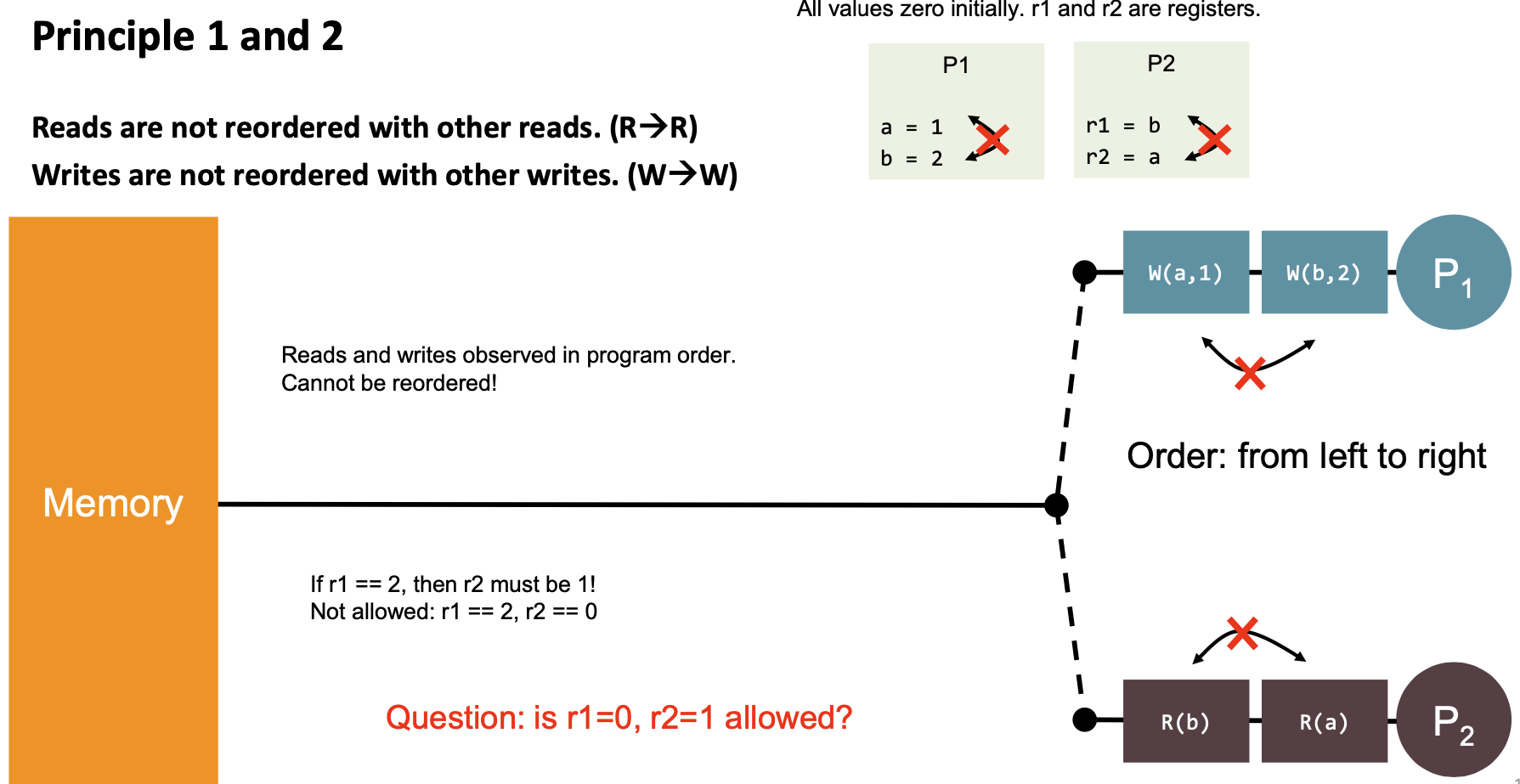 | Yes |
| 3 | “Writes are not reordered with older reads.” (R→W) | 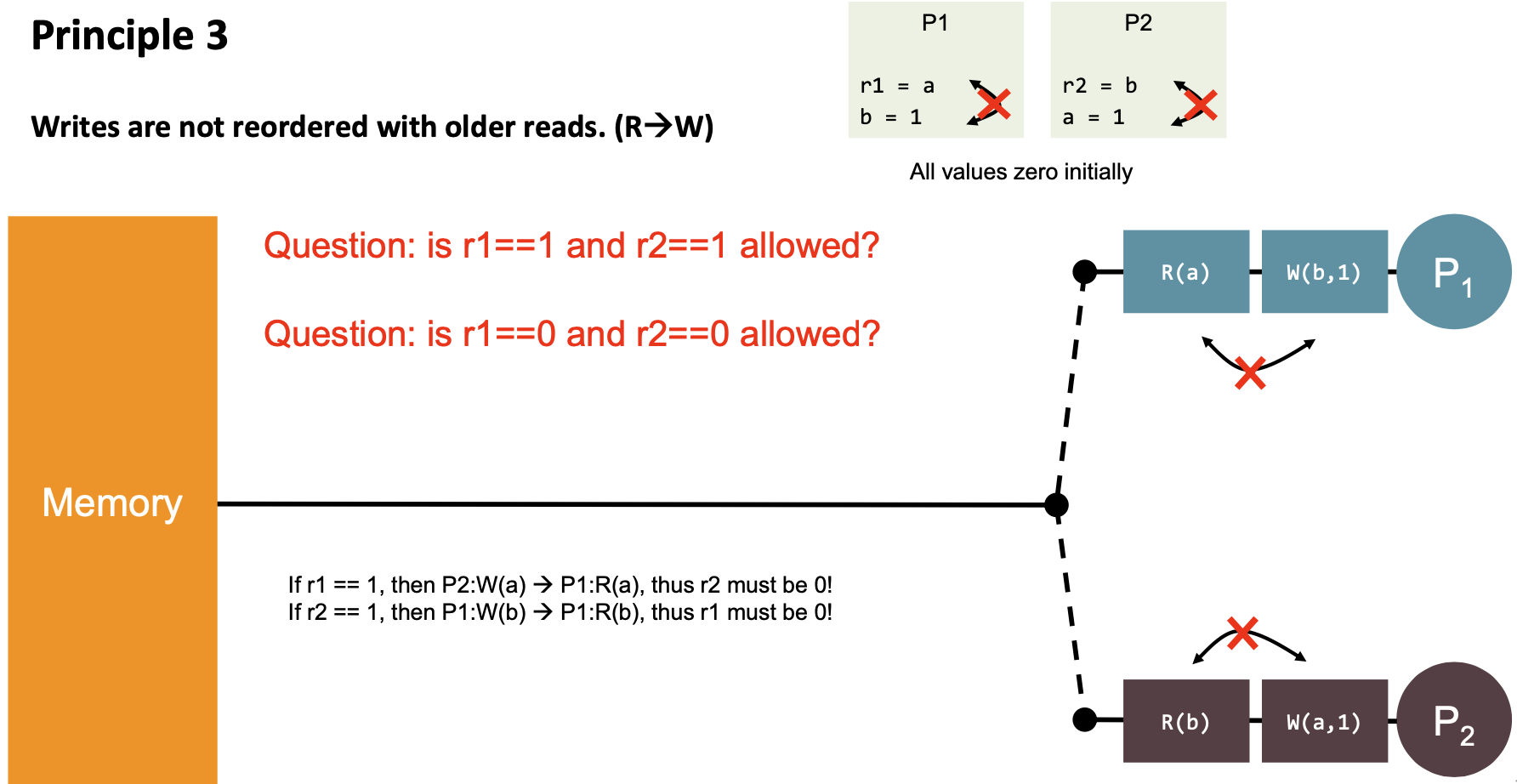 | No, Yes |
| 4 | “Reads may be reordered with older writes to different locations but not with older writes to the same location.” (NO W→R!) | 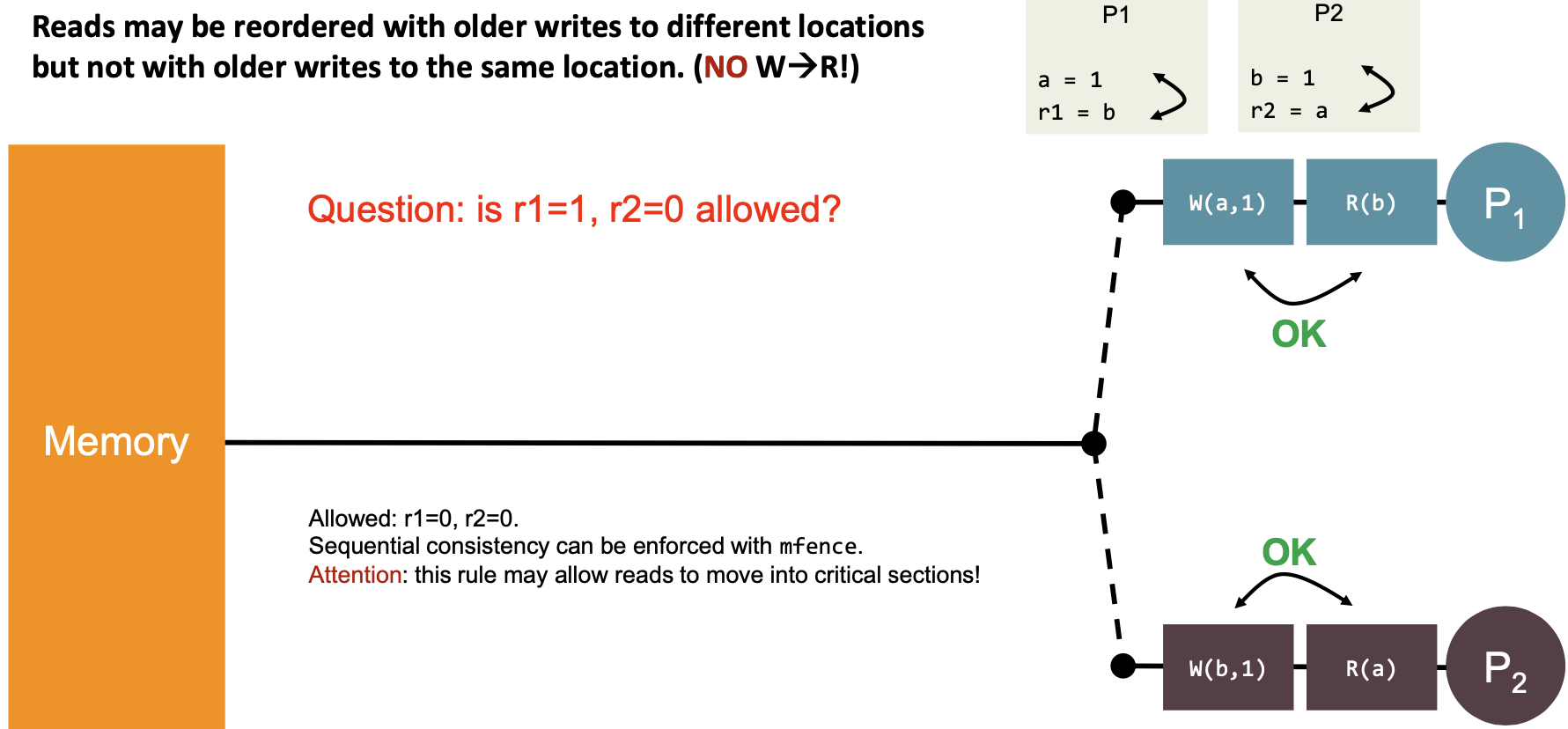 | Yes |
| 5 | “In a multiprocessor system, memory ordering obeys causality.” (memory ordering respects transitive visibility) | 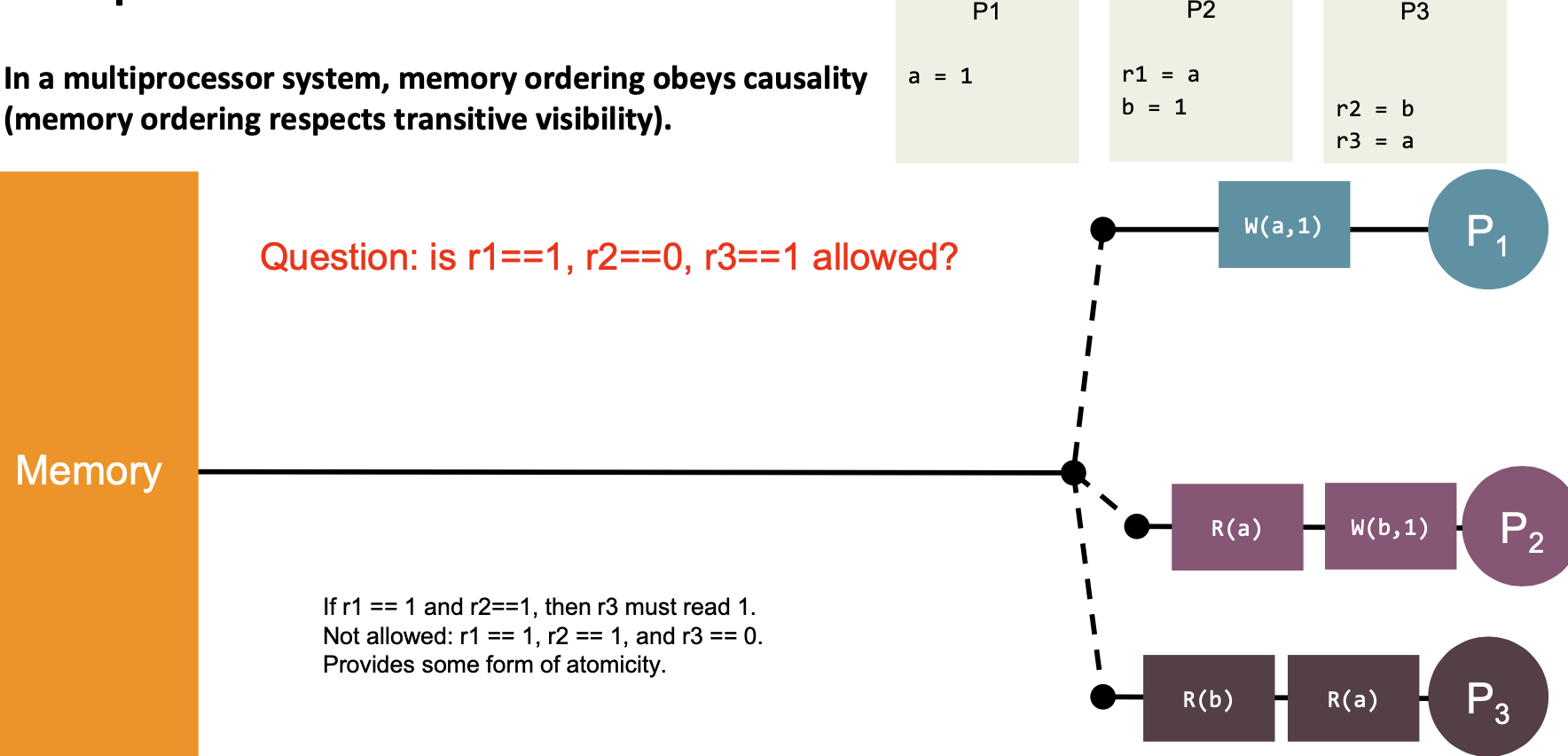 | Yes |
| 6 | “In a multiprocessor system, writes to the same location have a total order.” (implied by cache coherence) | 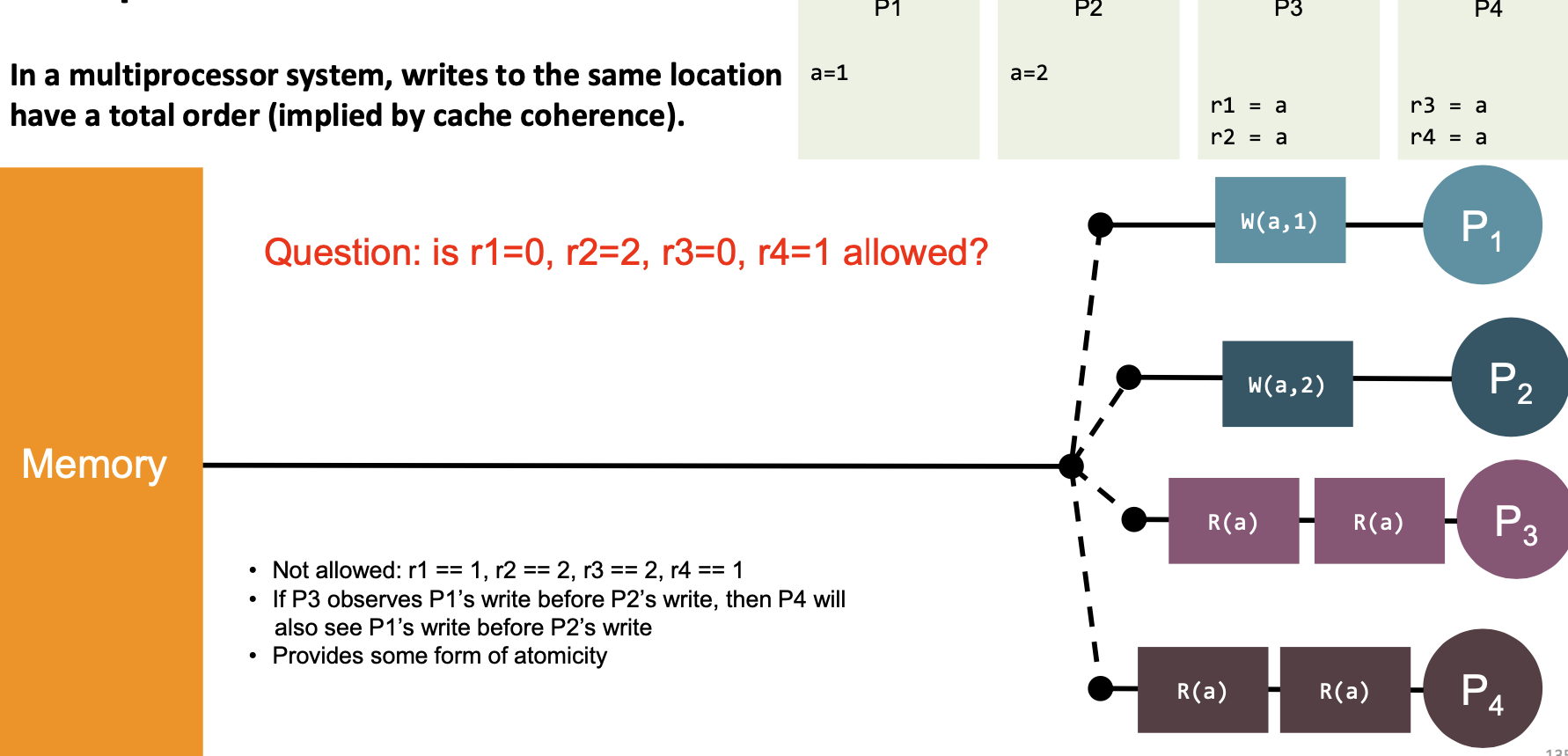 | Yes |
| 7 | “In a multiprocessor system, locked instructions have a total order.” (enables synchronized programming!) | 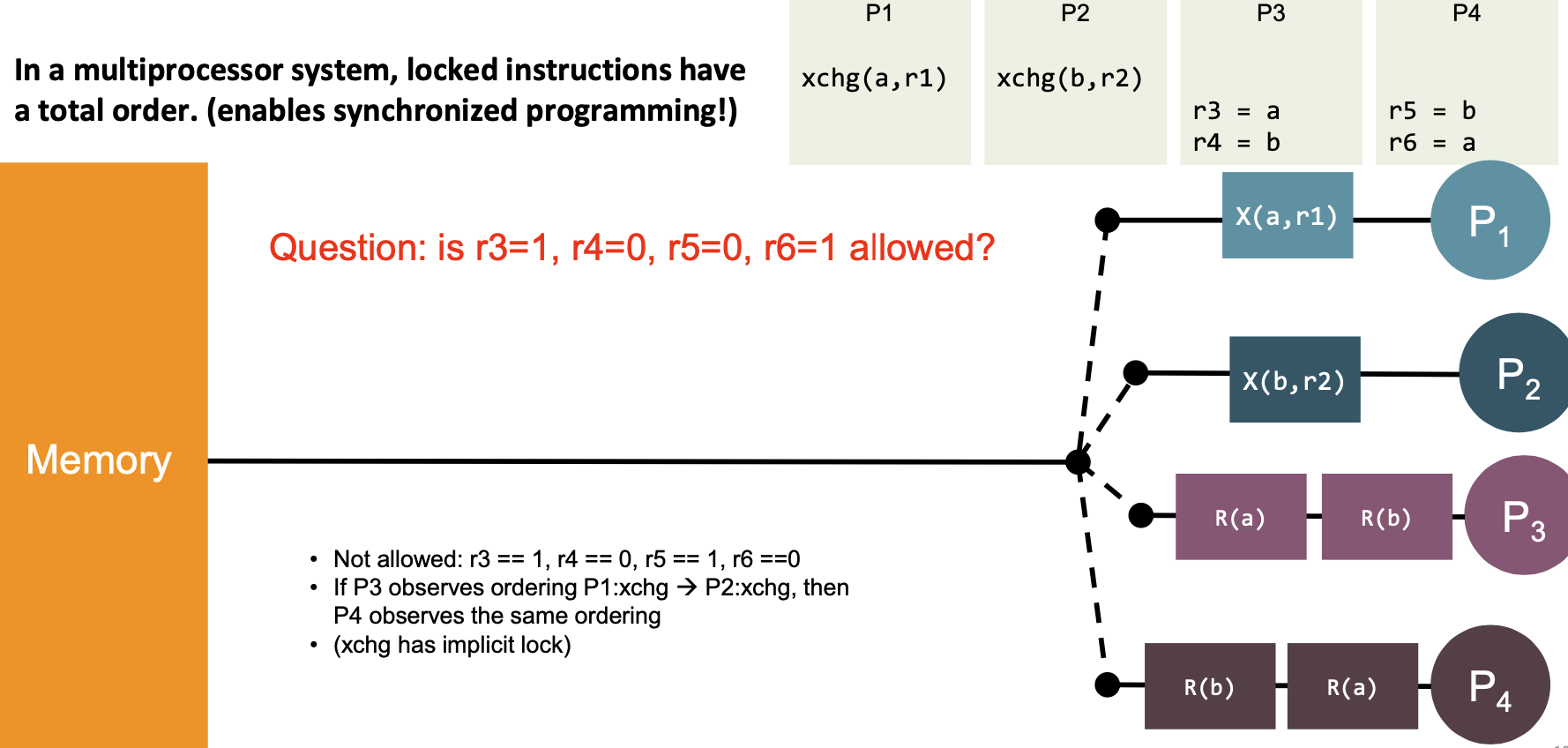 | Yes |
| 8 | “Reads and writes are not reordered with locked instructions. “ (enables synchronized programming!) | 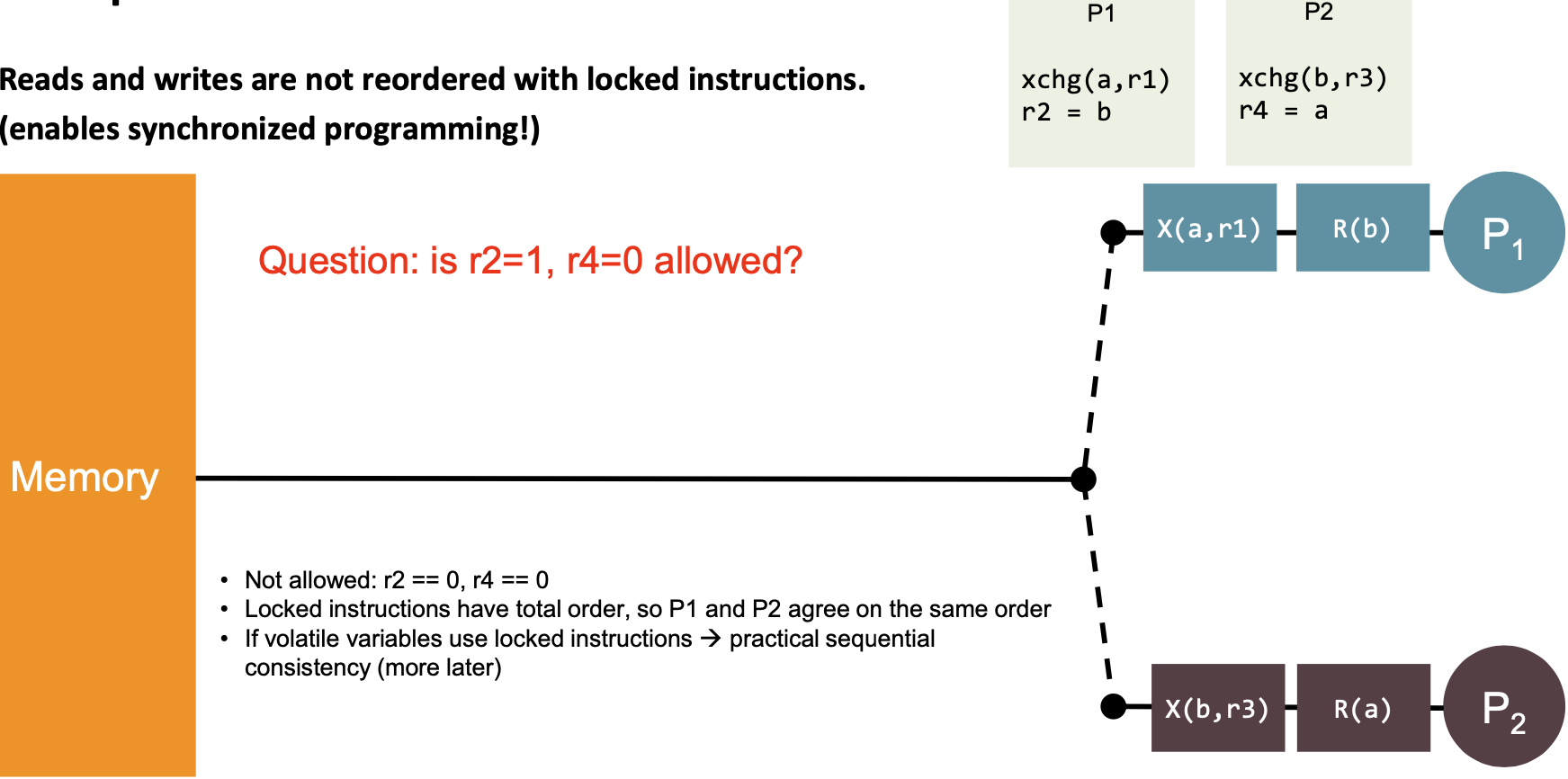 | Yes |
Language Memory Models
Java and C++ high-level overview
Relaxed memory model
- No global visibility ordering of operations
- Allows for standard compiler optimizations
But
- Program order for each thread (sequential semantics)
- Partial order on memory operations (with respect to synchronizations)
- Visibility function defined
Correctly synchronized programs guarantee sequential consistency.
Incorrectly synchronized programs:
- Java: maintain safety and security guarantees
- Type safety etc. (require behavior bounded by causality)
- C++: undefined behavior
- No safety (anything can happen/change)
Communication between threads: Intuition
Not guaranteed unless by:
- Synchronization
- Volatile/atomic variables
- Specialized functions/classes (e.g., java.util.concurrent, …)

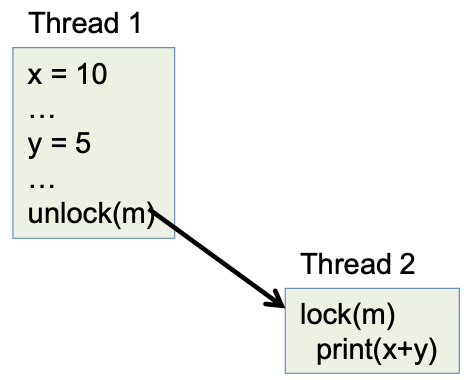
Locks synchronize threads and memory

Memory model semantics of locks
All memory accesses before an unlock are ordered before and are visible to any memory access after a matching lock!
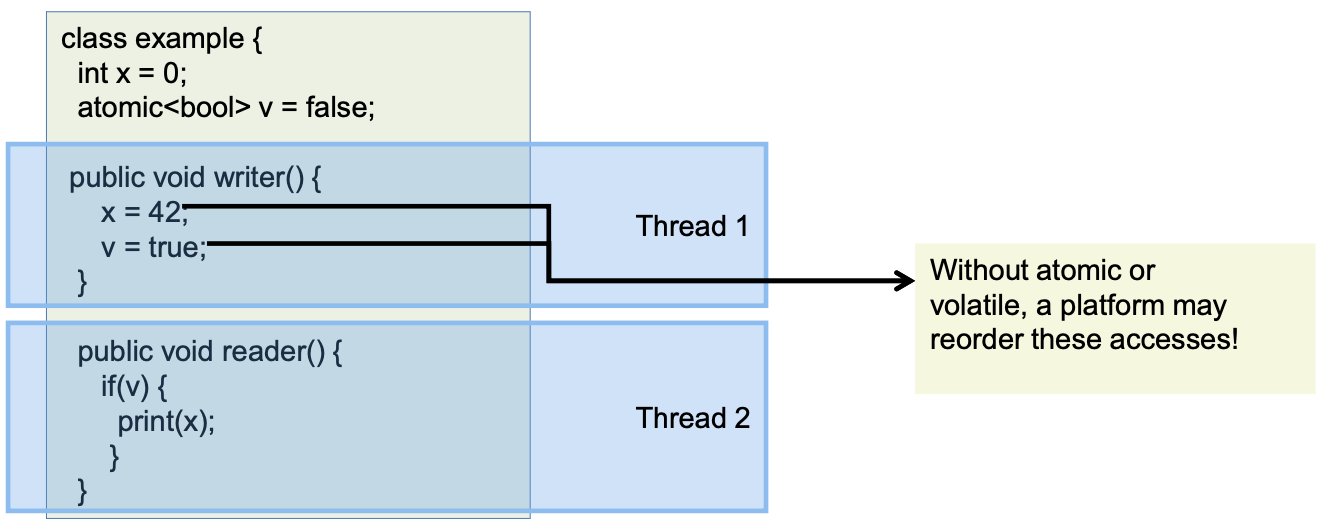
Memory model semantics of synchronization variables
Variables can be declared volatile (Java) or atomic (C++)
- Reads and writes to synchronization variables are totally ordered with respect to all threads
- Must not be reordered with normal reads and writes
The compiler
- Must not allocate synchronization variables in registers
- Must not swap variables with synchronization variables
- May need to issue memory fences/barriers
Write to a synchronization variable
- Similar memory semantics as unlock (no process synchronization though!)
Read from a synchronization variable
- Similar memory semantics as lock (no process synchronization though!)
Intuitive memory model rules
- Java/C++: Correctly synchronized programs will execute sequentially consistent
- Correctly synchronized = data-race free
- iff all sequentially consistent executions are free of data races
- Two accesses to a shared memory location form a data race in the execution of a program if
- The two accesses are from different threads
- At least one access is a write and
- The accesses are not synchronized
Conflicting Accesses
Two memory accesses conflict if they can happen at the same time (in happens-before) and one of them is a write (store)
Such a code is said to have a “race condition”, or data-race.
This can be avoided by using critical regions which guarantee mutually exclusive access to a set of operations.