Cache coherence
Cache coherence is a fundamental concept in computer architecture, particularly in systems with multiple processors or cores that share access to a common memory.
In a multi-processor system, each processor often has its own cache memory to store frequently used data for faster access. Cache coherence ensures that all processors observe a consistent view of memory, despite the presence of individual caches.
The need for cache coherence arises because each processor can have a local copy of a portion of the main memory in its cache. When one processor updates or modifies its local copy, other processors should be made aware of this change to maintain a consistent and correct view of the shared memory.
Example
- Which one is valid after local updates?
- Cache coherence manages the existence of multiple copies
| Exclusive Hierarchical Caches | Shared Hierarchical Caches | Shared Hierarchical Caches with MT |
|---|---|---|
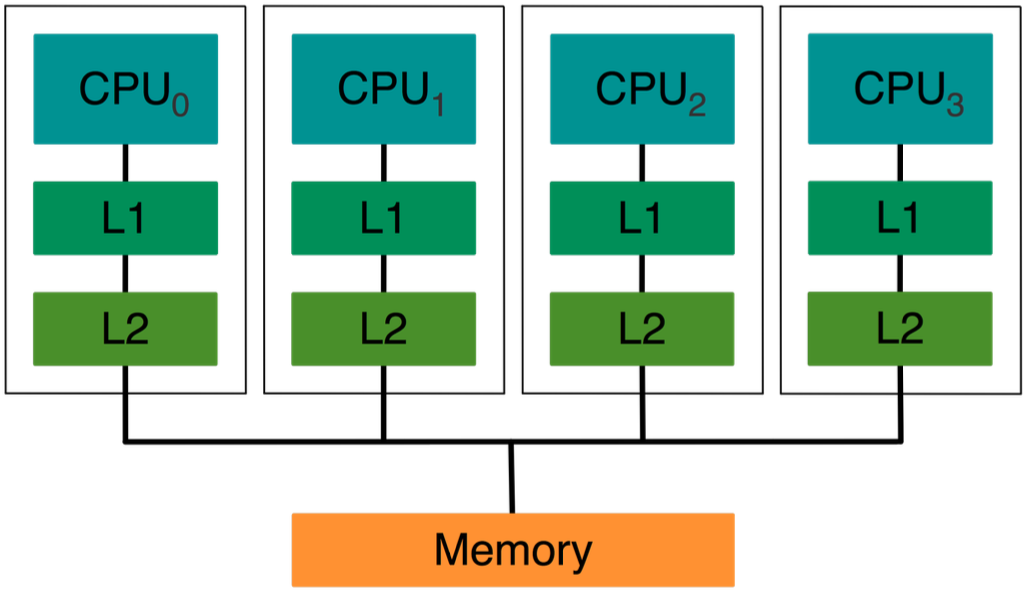 | 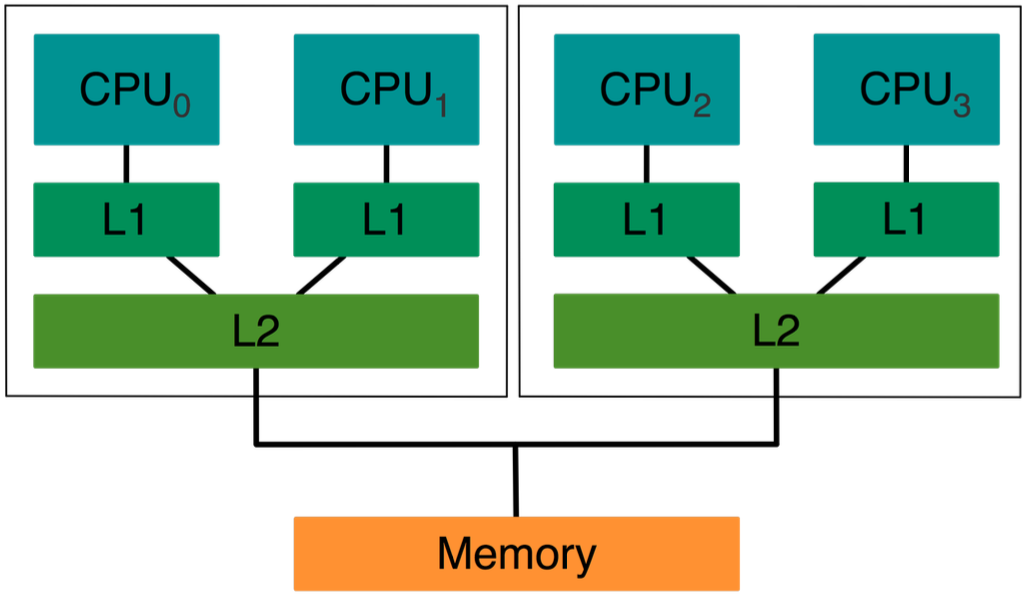 | 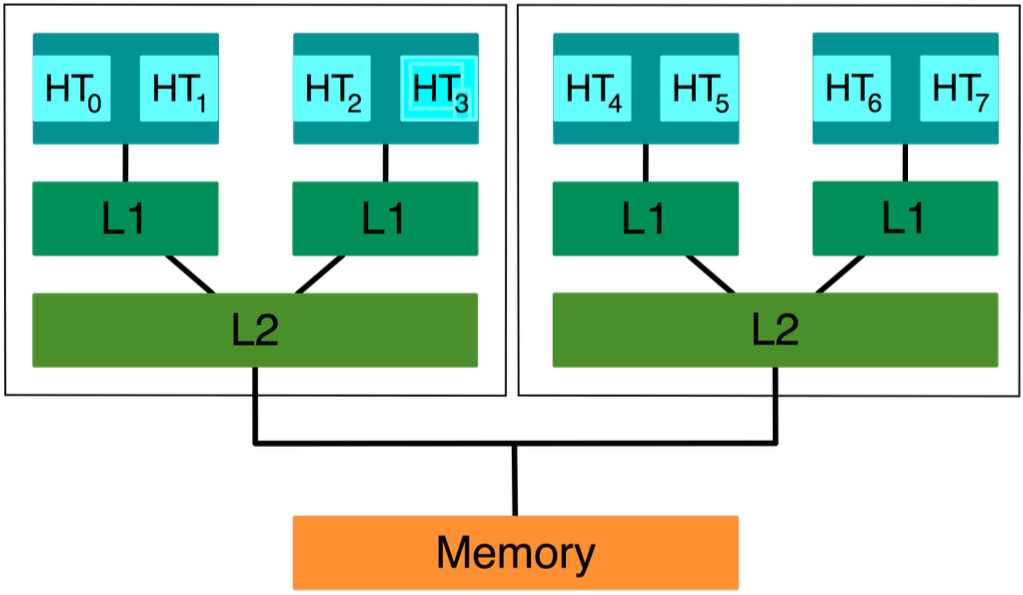 |
Cache coherence requirements
A memory system is coherent if it guarantees the following:
- Write propagation (updates are eventually visible to all readers)
- Write serialization (writes to the same location must be observed in order)
Everything else: memory model issues.
Write-through Cache
- CPU0 reads
Xfrom memory- loads
X=0into its cache
- loads
- CPU1 reads
Xfrom memory- loads
X=0into its cache
- loads
- CPU0 writes
X=1- stores
X=1in its cache - stores
X=1in memory
- stores
- CPU1 reads
Xfrom its cache- loads X=0 from its cache
- CPU1 may wait for update!
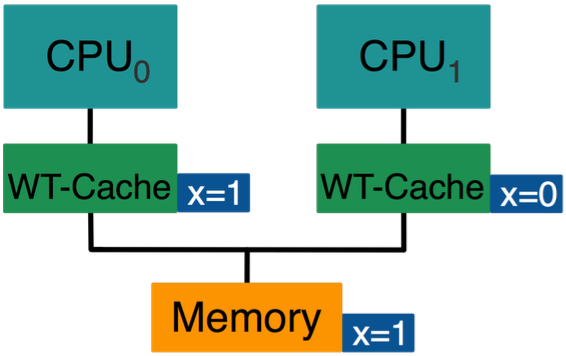
Requires write propagation!
Write-back Cache
- CPU0 reads
Xfrom memory- loads
X=0into its cache
- loads
- CPU1 reads
Xfrom memory- loads
X=0into its cache
- loads
- CPU0 writes
X=1- stores
X=1in its cache
- stores
- CPU1 writes
X =2- stores
X=2in its cache
- stores
- CPU1 writes back cache line
- stores
X=2in in memory
- stores
- CPU0 writes back cache line
- stores
X=1in memory
- stores
Later store
X=2from CPU1 lostRequires write serialization!
Cache coherence protocols
Programmers can hardly deal with unpredictable behavior!
- Cache controller maintains data integrity
- All writes to different locations are visible
Snooping
- Through a shared bus or (broadcast) network, the cache controller “snoops” all transactions
- Monitors and changes the state of the cache’s data
- Works at small scale, challenging at large-scale
Directory-based
- Record information necessary to maintain coherence
- e.g., owner and state of a line etc.
- Central/Distributed directory for cache line ownership
- Scalable but more complex/expensive
- e.g., Intel Xeon Phi KNC
Cache Coherence Parameters
Concerns/Goals
- Performance
- Implementation cost (chip space, more important: dynamic energy)
- Correctness
- (Memory model side effects)
Issues
- Detection
- when does a controller need to act?
- Enforcement
- how does a controller guarantee coherence?
- Precision of block sharing (per block, per sub-block?)
- Block size
- cache line size?
Problem 1: Stale reads
Cache 1 holds value that was already modified in cache 2.
- Disallow this state
- Invalidate all remote copies before allowing a write to complete
Problem 2: Lost update
Incorrect write back of modified line writes main memory in different order from the order of the write operations or overwrites neighboring data
Solution:
Disallow more than one modified copy
Invalidation vs. update
Invalidation-based
On each write of a shared line, it has to invalidate copies in remote caches
Simple implementation for bus-based systems:
- Each cache snoops
- Invalidate lines written by other CPUs
- Signal sharing for cache lines in local cache to other caches
Only write misses hit the bus (works with write-back caches)
- Subsequent writes to the same cache line are local
- → Good for multiple local writes to the same line (in the same cache)
Update-based
Local write updates copies in remote caches
- Can update all CPUs at once
- Multiple writes cause multiple updates (more traffic)
All sharers continue to hit cache line after one core writes
Implicit assumption: shared lines are accessed often
- Supports producer-consumer pattern well
- Many (local) writes may waste bandwidth!
Hybrid forms are possible!
MESI Cache Coherence aka. “Illinois protocol”
MESI is a cache coherence protocol used in multiprocessor systems to maintain consistency among caches. The name MESI is an acronym that stands for the four possible states that a cache line can be in:
- Modified (M):
- The cache line is present in the cache, and it has been modified.
- This means that the data in the cache differs from the data in the main memory.
- Memory is stale
- Exclusive (E):
- The cache line is present in the cache, and it’s not present in any other caches.
- The data in the cache is the same as in the main memory, and no other caches have it.
- Memory is up to date
- Shared (S):
- The cache line is present in the cache, and it may be present in other caches as well.
- The data in the cache is consistent with the main memory, and other caches may also have a copy.
- Memory is up to date
- Invalid (I):
- The cache line is not valid or has been marked as invalid.
- The data in the cache is not reliable or up-to-date.
- Line is not in cache
The MESI protocol operates based on a set of rules that govern state transitions in response to read and write operations. Here’s a brief overview of how MESI works:
- Modified to Shared (Write-back):
- When a processor writes to a cache line in the
Modifiedstate, it must update the main memory with the modified data and change its state toShared.- This ensures that other caches can now have a consistent copy.
- When a processor writes to a cache line in the
- Exclusive to Modified (Write):
- If a processor wants to write to a cache line in the
Exclusivestate, it can do so without checking with other caches since it’s the only cache with that data. - The state transitions to
Modified.
- If a processor wants to write to a cache line in the
- Shared to Invalid (Write):
- If a processor writes to a cache line in the
Sharedstate, it must invalidate copies in other caches to maintain consistency. - The state transitions to
Invalid.
- If a processor writes to a cache line in the
- Any state to Shared (Read):
- When a processor reads a cache line, it checks if any other caches have a copy.
- If no other caches have it, the state transitions to
Exclusive(if it’sModified) or remains inShared.
- Modified to Invalid (Write-back):
- If a processor in the
Modifiedstate is invalidated by another processor, it must write the modified data back to main memory and change its state toInvalid.
- If a processor in the
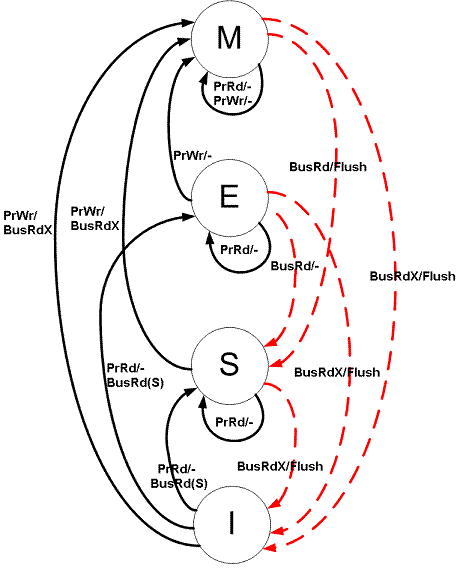
The MESI protocol helps prevent inconsistencies and conflicts in multiprocessor systems by ensuring that caches have a consistent view of shared data. It’s a widely used protocol for maintaining cache coherence due to its simplicity and effectiveness.
Terminology
Clean line:
- Content of cache line and main memory is identical (a.k.a memory is up to date)
- Can be evicted without write-back
Dirty line:
- Content of cache line and main memory differ (a.k.a memory is stale)
- Needs to be written back eventually
- Timing depends on protocol details
Bus transaction:
A signal on the bus that can be observed by all caches, which usually is blocking.
Local read/write:
- A load/store operation originating at a core connected to the cache.
MOESI
- Modified (M): Modified Exclusive
- No copies in other caches, local copy dirty
- Memory is stale, cache supplies copy (reply to
BusRd*)
- Owner (O): Modified Shared
- Exclusive right to make changes
- Other S copies may exist (“dirty sharing”)
- Memory is stale, cache supplies copy (reply to
BusRd*)
- Exclusive (E):
- Same as MESI
- (one local copy, up to date memory)
- Shared (S):
- Unmodified copy may exist in other caches
- Memory is up to date unless an O copy exists in another cache
- Invalid (I):
- Same as MESI
MESIF
Same as MESI, but adds:
- Forward (F):
- Special form of S state
- other caches may have line in S
- Most recent requester of line is in F state
- Cache acts as responder for requests to this line
- Special form of S state
Multi-level caches
Most systems have multi-level caches.
Problem:
only “last level cache” is connected to bus or network
- Snoop requests are relevant for inner-levels of cache (L1)
- Modifications of L1 data may not be visible at L2 (and thus the bus)
L1/L2 modifications:
- On BusRd check if line is in M state in L1
- It may be in E or S in L2!
- On
BusRdX(*)send invalidations to L1 - Everything else can be handled in L2
If L1 is write through, L2 could “remember” state of L1 cache line – May increase traffic though
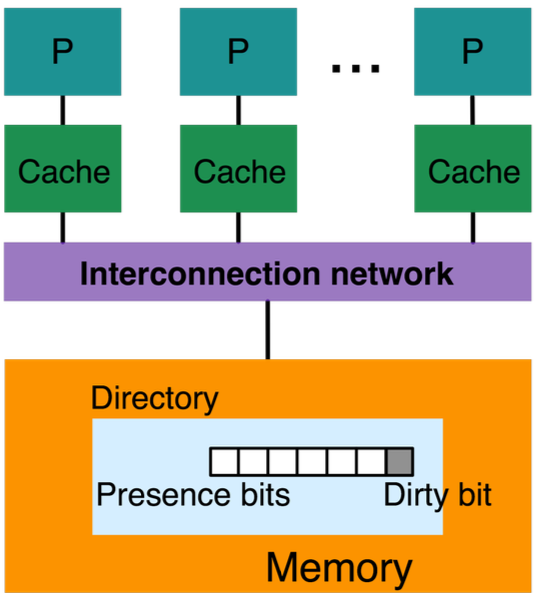
Directory-based cache coherence
Snooping does not scale
- Bus transactions must be globally visible
- Implies broadcast
- Typical solution: tree-based (hierarchical) snooping
- Root becomes a bottleneck
Directory-based schemes are more scalable
- Directory (entry for each CL) keeps track of all owning caches
- Point-to-point update to involved processors
- No broadcast
- Can use specialized (high-bandwidth) network, e.g., HT, QPI …
Basic Scheme
System with $N$ processors $P_i$ For each memory block (size: cache line) maintain a directory entry
- $N$ presence bits
- Set if block in cache of $P_i$
- $1$ dirty bit
Read miss
$P_i$ intends to read, but misses.
If dirty bit in the directory is off:
- Read from main memory
- Set
presence[i] - Supply data to reader
If dirty bit is on:
- Recall cache line from $P_j$ (determined by
presence[]) - Update memory
- Unset dirty bit, block shared
- Set
presence[i] - Supply data to reader
Write miss
If dirty bit in the directory is off:
- Send invalidations to all processors $P_j$ with
presence[j] = 1 - Unset presence bit for all processors
- Set dirty bit
- Set
presence[k], owner $P_i$
If dirty bit is on:
- Recall cache line from owner $P_j$ (determined by
presence[]) - Update memory
- Unset
presence[j] - Set
presence[i]- Dirty bit remains set
- Supply data to writer