MPI
A simple MPI program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <mpi.h>
int main(int argc, char **argv) {
int myrank, sbuf=23, rbuf=32;
MPI_Init(&argc, &argv);
/* Find out my identity in the default communicator */
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0) {
MPI_Send(&sbuf, /* message buffer */
1, /* one data item */
MPI_INT, /* data item is an integer */
rank, /* destination process rank */
99, /* user chosen message tag */
MPI_COMM_WORLD); /* default communicator */
} else {
MPI_Recv(&rbuf, MPI_DOUBLE, 0, 99, MPI_COMM_WORLD, &status);
printf("received: %i\n", rbuf);
}
MPI_Finalize();
}
MPI supports Shared Memory and PGAS-style
PGAS: Partitioned Global Address Space
- Support for shared memory in SMM domains through Shared memory windows
- Support for Remote Memory Access Programming: Direct use of RDMA through One Sided
- Enhanced support for message passing communication:
- Scalable topologies
- More non-blocking features
The Message-Passing Model
- A process is (traditionally) a program counter and address space (with resources)
- Processes may have multiple threads (program counters and associated stacks) sharing a single address space.
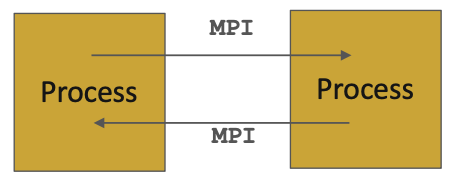
MPI is for communication among processes, which have separate address spaces.
Inter-process communication consists of
- synchronization
- movement of data from one process’s address space to another’s.
Reasons for Using MPI
- Standardization - MPI is the only message passing library which can be considered a standard. It is supported on virtually all HPC platforms. Practically, it has replaced all previous message passing libraries
- Portability - There is no need to modify your source code when you port your application to a different platform that supports (and is compliant with) the MPI standard
- Performance Opportunities - Vendor implementations should be able to exploit native hardware features to optimize performance
- Functionality - Rich set of features
- Availability - A variety of implementations are available, both vendor and public domain
- MPICH/Open MPI are popular open-source and free implementations of MPI
- Vendors and other collaborators take MPICH and add support for their systems
Process Identification
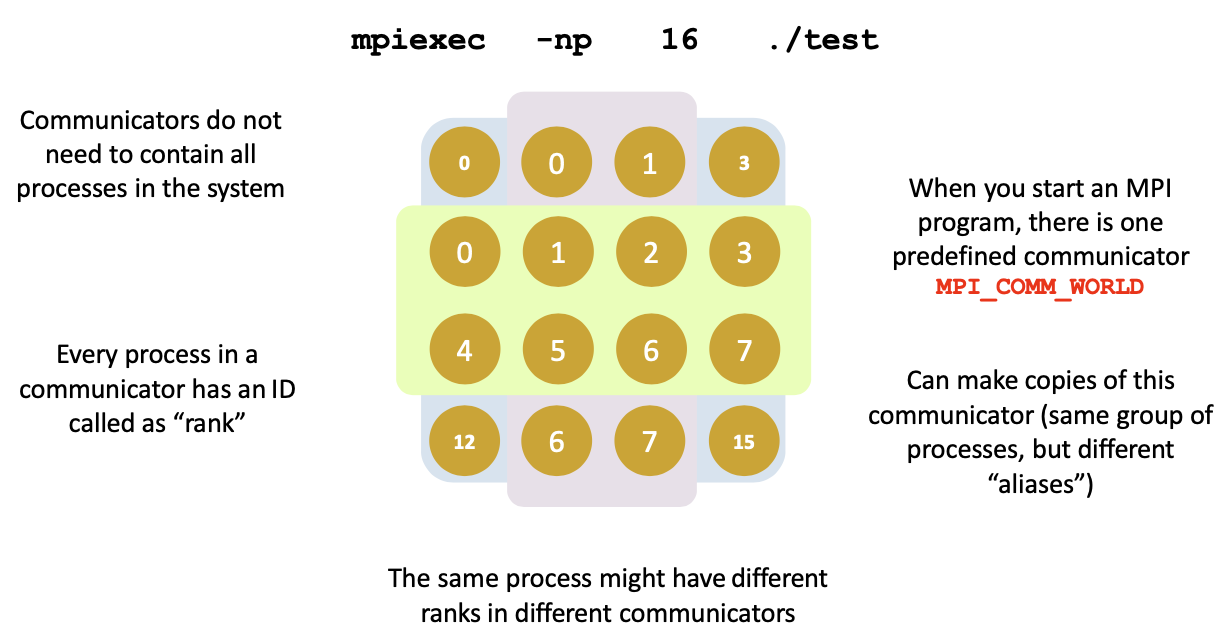
MPI processes can be collected into groups.
- Each group can have multiple colors (sometimes called context)
group + color == communicator(like a name for the group)- When an MPI application starts, the group of all processes is initially given a predefined name called
MPI_COMM_WORLD - The same group can have many names, but simple programs do not have to worry about multiple names
A process is identified by a unique number within each communicator, called rank.
- For two different communicators, the same process can have two different ranks:
- the meaning of a “rank” is only defined when you specify the communicator
Data Communication
Data communication in MPI is like email exchange:
- one process sends a copy of the data to another process (or a group of processes),
- and the other process receives it.

Communication requires the following information
Sender has to know:
- Whom to send the data to (receiver’s process rank)
- What kind of data to send (100 integers or 200 characters, etc)
- A user-defined “tag” for the message
- think of it as an email subject
- it allows the receiver to understand what type of data is being received
Receiver “might” have to know:
- Who is sending the data
- OK if the receiver does not know; in this case sender rank will be
MPI_ANY_SOURCE, meaning anyone can send
- OK if the receiver does not know; in this case sender rank will be
- What kind of data is being received
- partial information is OK: I might receive up to 1000 integers
- What the user-defined “tag” of the message is
- OK if the receiver does not know; in this case tag will be
MPI_ANY_TAG
- OK if the receiver does not know; in this case tag will be
When sending data, the sender has to specify the destination process’ rank.
The receiver has to specify the source process’ rank.
MPI_ANY_SOURCEis a special “wild-card” source that can be used by the receiver to match any source.
More Details on User “Tags” for Communication
Messages are sent with an accompanying user-defined integer tag, to assist the receiving process in identifying the message. For example, if an application is expecting two types of messages from a peer, tags can help distinguish these two types.
MPI_ANY_TAGis a special “wild-card” tag that can be used by the receiver to match any tag.
Non-Blocking Communication
- Non-blocking (asynchronous) operations return (immediately) “request handles” that can be waited on and queried
MPI_ISEND(start, count, datatype, dest, tag, comm, request)MPI_IRECV(start, count, datatype, src, tag, comm, request)MPI_WAIT(request, status)
- Non-blocking operations allow overlapping computation and communication
- One can also test without waiting using
MPI_TESTMPI_TEST(request, flag, status)
- Anywhere you use
MPI_SENDorMPI_RECV, you can use the pair ofMPI_ISEND/MPI_WAITorMPI_IRECV/MPI_WAIT - Combinations of blocking and non-blocking sends/receives can be used to synchronize execution instead of barriers
Multiple Completions
It is sometimes desirable to wait on multiple requests:
MPI_Waitall(count, array_of_requests, array_of_statuses)MPI_Waitany(count, array_of_requests, &index, &status)MPI_Waitsome(count, array_of_requests, array_of_indices, array_of_statuses)
There are corresponding versions of test for each of these
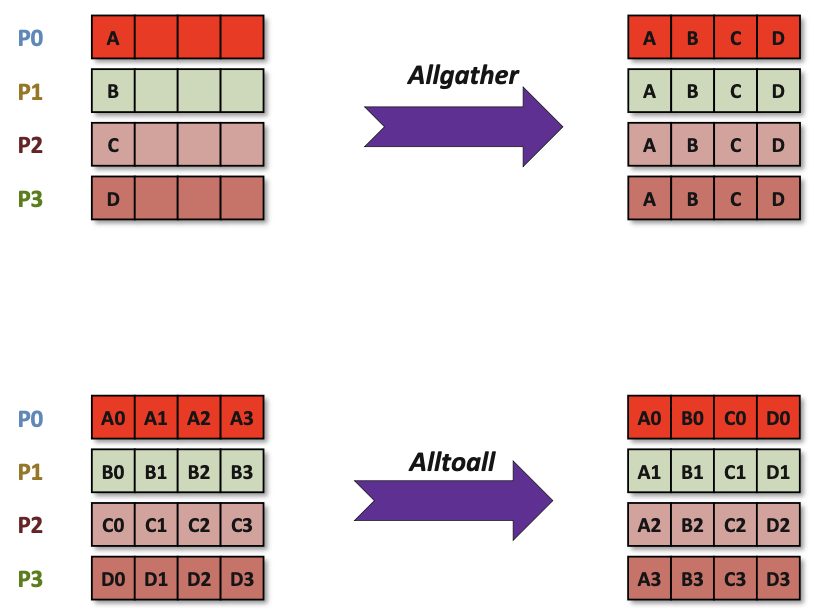
Introduction to Collective Operations in MPI
MPI also supports communications among groups of processors
- not absolutely necessary for programming (but very nice!)
- essential for performance
Collective operations are called by all processes in a communicator.
MPI_BCASTdistributes data from one process (the root) to all others in a communicator.
MPI_REDUCEcombines data from all processes in the communicator and returns it to one process.
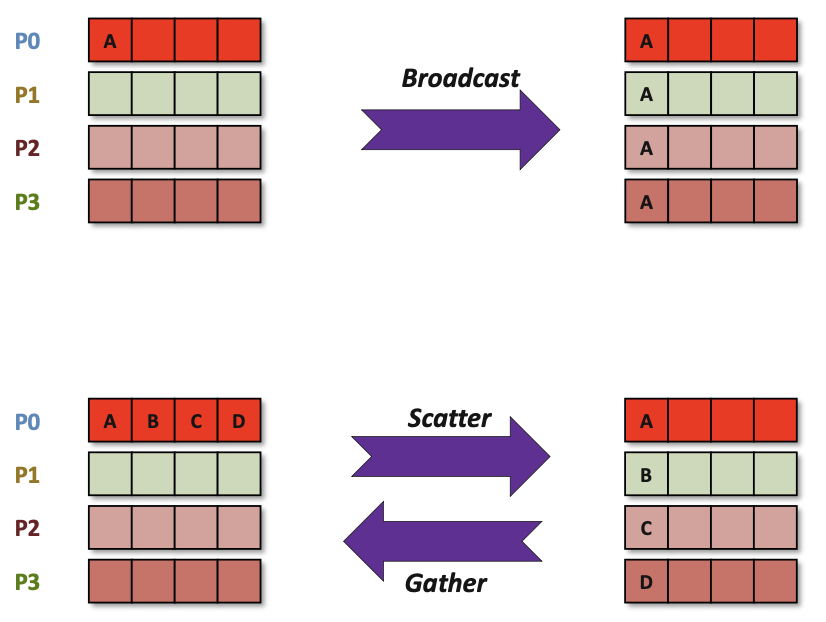
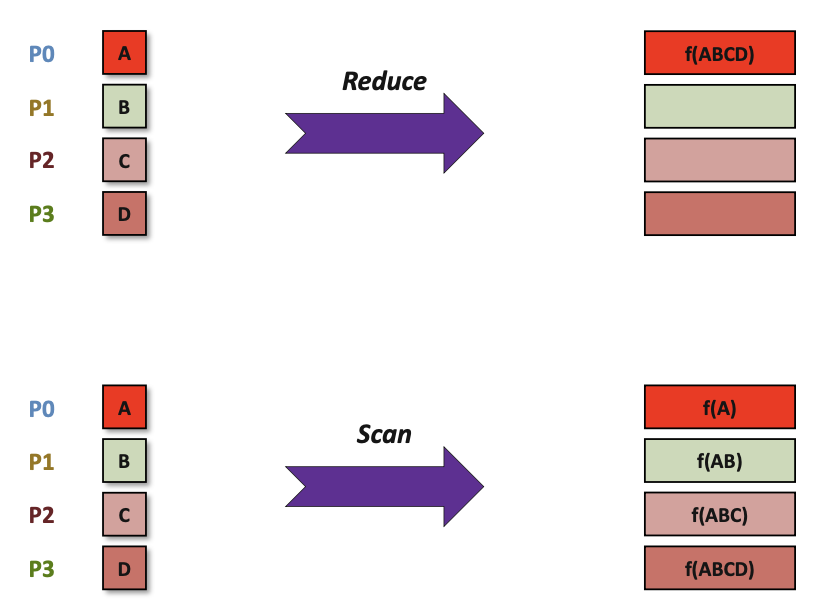
In many numerical algorithms, SEND/RECV can be replaced by BCAST/REDUCE, improving both simplicity and efficiency.
Communication and computation is coordinated among a group of processes in a communicator.
Tags are not used; different communicators deliver similar functionality.

Non-blocking collective operations in MPI-3
There are 3 classes of operations:
- synchronization,
- data movement,
- collective computation.
Synchronization
Blocks until all processes in the group of the communicator call it.
A process cannot get out of the barrier until all other processes have reached the barrier
- “All” versions deliver results to all participating processes
- “V” versions (stands for vector) allow the chunks to have different sizes
MPI Built-in Collective Computation Operations
| Operation | Description |
|---|---|
MPI_MAX | Maximum |
MPI_MIN | Minimum |
MPI_PROD | Product |
MPI_SUM | Sum |
MPI_LAND | Logical AND |
MPI_LOR | Logical OR |
MPI_LXOR | Logical XOR |
MPI_BAND | Bitwise AND |
MPI_BOR | Bitwise OR |
MPI_BXOR | Bitwise XOR |
MPI_MAXLOC | Maximum and Location |
MPI_MINLOC | Minimum and Location |
Reduce Implementation: a tree-structured global sum
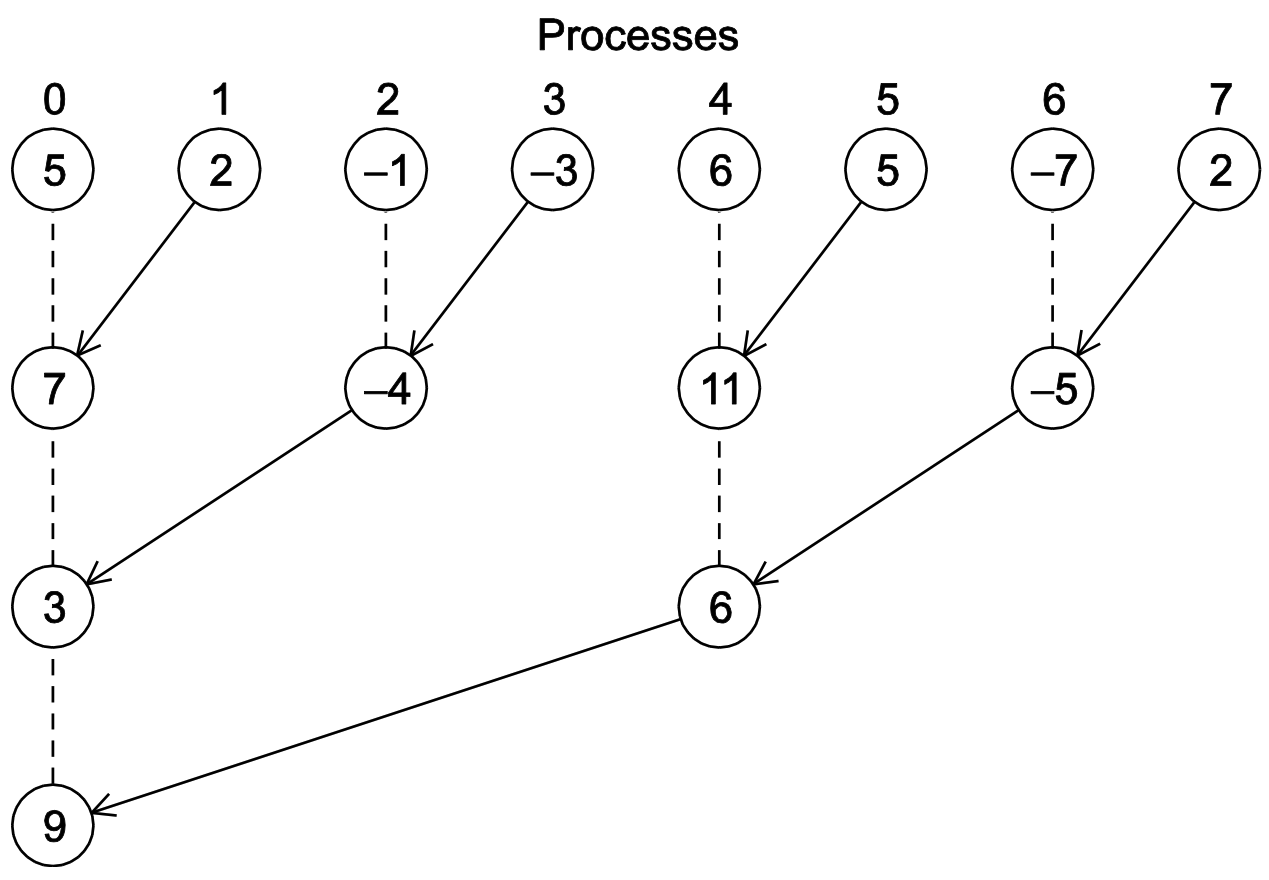
- In the first phase:
- Process 1 sends to 0, 3 sends to 2, 5 sends to 4, and 7 sends to 6.
- Processes 0, 2, 4, and 6 add in the received values.
- Second phase:
- Processes 2 and 6 send their new values to processes 0 and 4, respectively.
- Processes 0 and 4 add the received values into their new values.
- Finally:
- Process 4 sends its newest value to process 0.
- Process 0 adds the received value to its newest value.
Broadcast Implementation
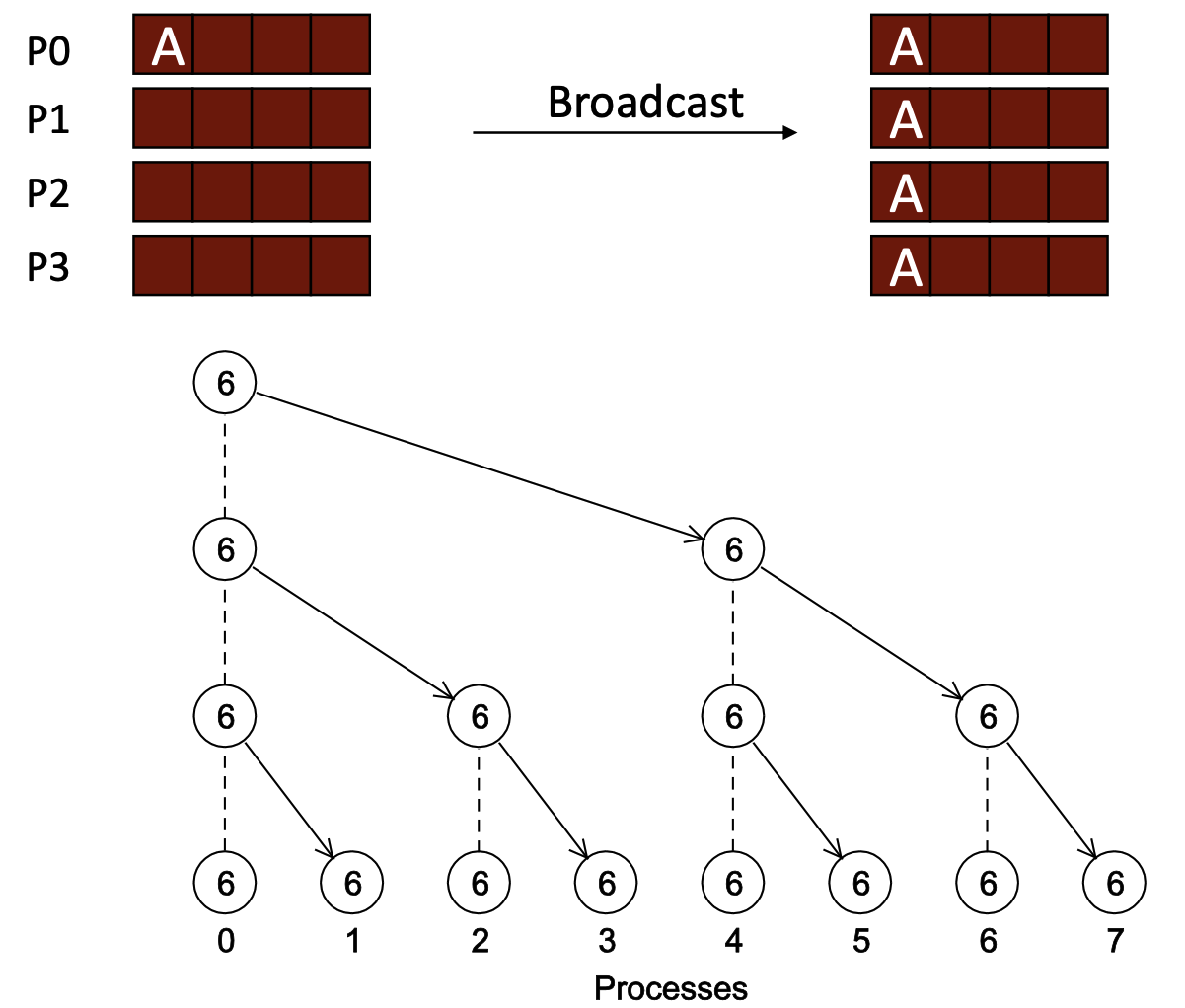
Allreduce != Reduce + Broadcast
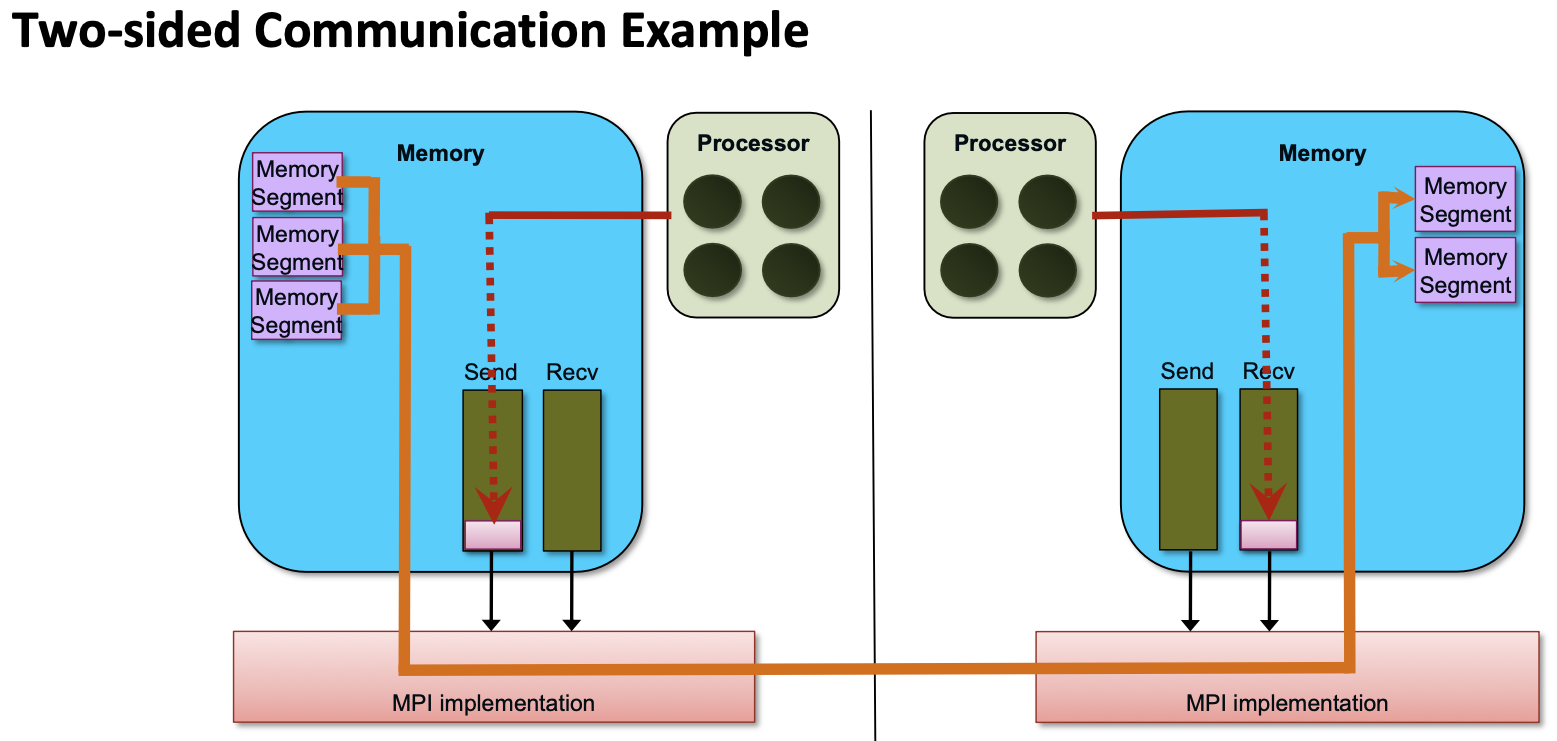
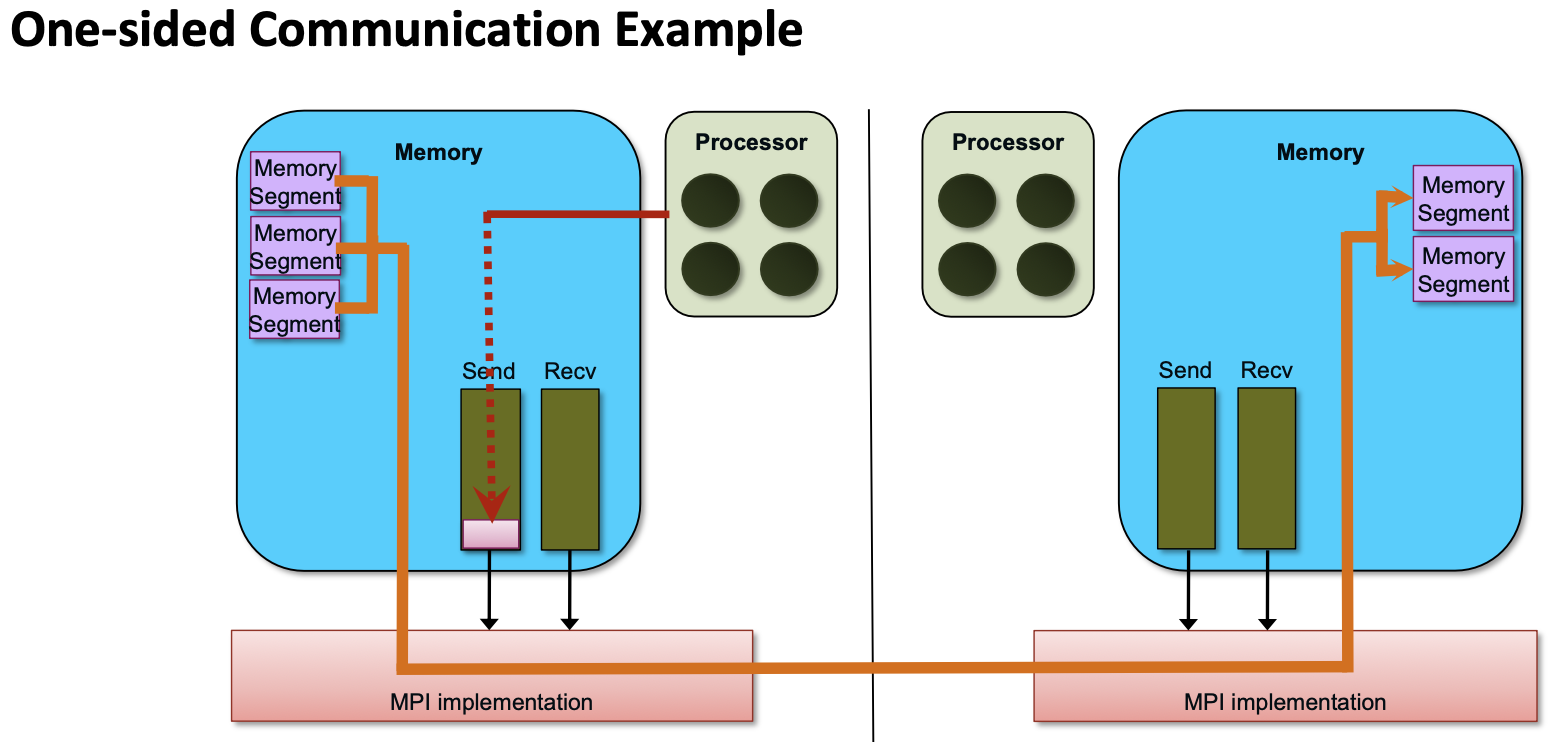
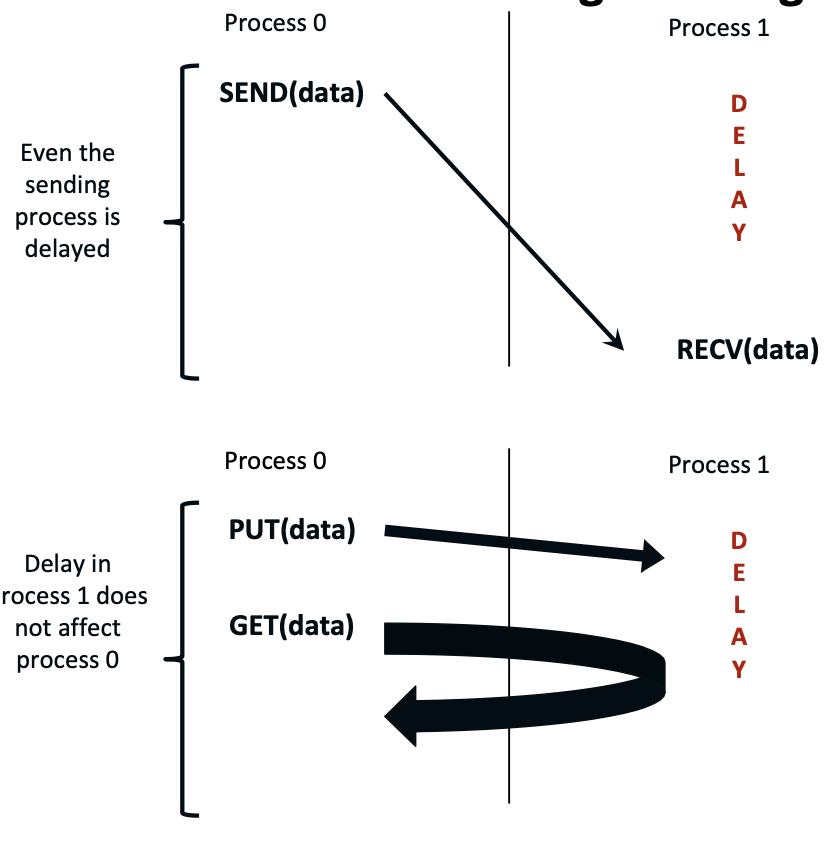
One- and Two-sided Communication
The basic idea of one-sided communication models is to decouple data movement with process synchronization
- Should be able to move data without requiring that the remote process synchronize
- Each process exposes a part of its memory to other processes
- Other processes can directly read from or write to this memory
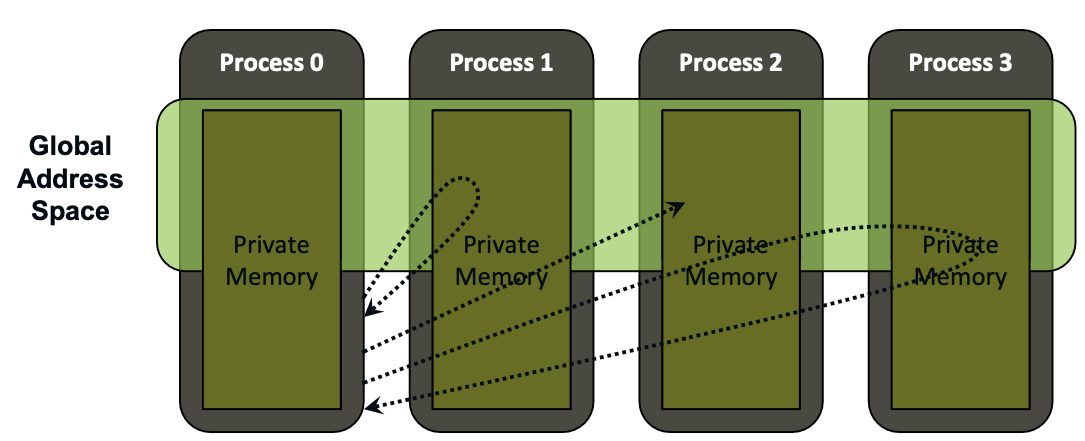
MPI Remote Memory Access
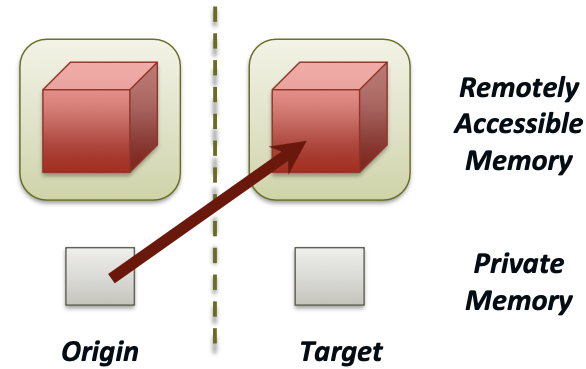
Creating Public Memory
Any memory used by a process is, by default, only locally accessible
X = malloc(100);
Once the memory is allocated, the user has to make an explicit MPI call to declare a memory region as remotely accessible
- MPI terminology for remotely accessible memory is a “window”
- A group of processes collectively create a “window”
Once a memory region is declared as remotely accessible, all processes in the window can read/write/update data to this memory without explicitly synchronizing with the target process
- MPI routines usually required for read/write/update of remote data
Window creation models
$4$ models exist:
MPI_WIN_ALLOCATE- You want to create a buffer and directly make it remotely accessible
- Create a remotely accessible memory region in an RMA window
- Only data exposed in a window can be accessed with RMA ops
MPI_WIN_CREATE- You already have an allocated buffer that you would like to make remotely accessible
MPI_WIN_CREATE_DYNAMIC- You don’t have a buffer yet, but will have one in the future
- You may want to dynamically add/remove buffers to/from the window
MPI_WIN_ALLOCATE_SHARED- You want multiple processes on the same node to share a buffer
Data movement
MPI provides ability to read, write and atomically update (modify) data in remotely accessible memory regions
MPI_PUT- Move data from origin, to target
- Separate data description triples for origin and target
MPI_GET- Move data to origin, from target
- Separate data description triples for origin and target
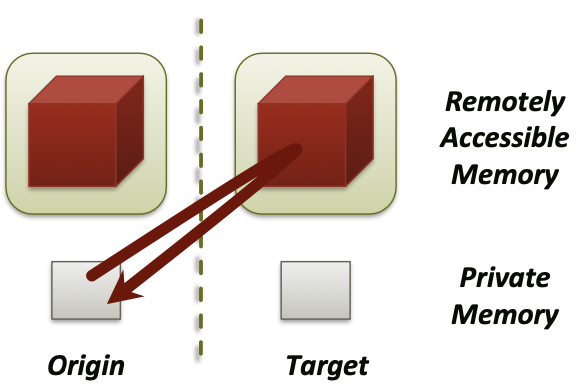
MPI_ACCUMULATE(atomic)MPI_GET_ACCUMULATE(atomic)MPI_COMPARE_AND_SWAP(atomic)MPI_FETCH_AND_OP(atomic)
Atomic: Accumulate
Atomic update operation (similar to a put)
- Reduces origin and target data into target buffer using op argument as combiner
- Available operations:
MPI_SUM,MPI_PROD,MPI_OR,MPI_REPLACE,MPI_NO_OP`,
- Predefined ops only, no user-defined operations
With Op =
MPI_REPLACE, you implement an atomicPUT
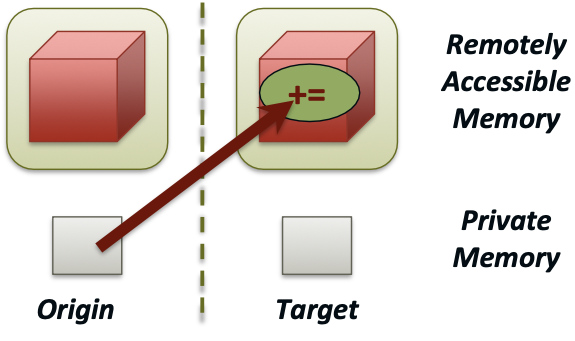
Atomic: Get Accumulate
Atomic read-modify-write
- Available operations:
MPI_SUM,MPI_PROD,MPI_OR,MPI_REPLACE,MPI_NO_OP
- You can use predefined operations only
- Result stored in target buffer
- Original data stored in result buffer
- Different data layouts between target/origin
- Basic type elements must match
Atomic
GETwithMPI_NO_OPAtomic
SWAPwithMPI REPLACE
Atomic Fetch_and_op, Compare_and_swap
FOP: Simpler version ofMPI_Get_accumulate
- All buffers share a single predefined datatype
- No count argument (it’s always 1)
- Simpler interface allows hardware optimization
CAS: Atomicswapif target value is equal to compare value
Ordering of Operations in MPI RMA
No guaranteed ordering for Put/Get operations
- Result of concurrent
Putsto the same location undefined - Result of Get concurrent with Put/Accumulate undefined
- Can be garbage in both cases
Result of concurrent accumulate operations to the same location are defined according to the order in which they occurred
- Atomic
put:Accumulatewith op =MPI_REPLACE - Atomic
get:Get_accumulatewith op =MPI_NO_OP
Accumulate operations from a given process are ordered by default.
- User can tell the MPI implementation that he does not require ordering as optimization hint with info when window is created.
- You can ask for only the needed orderings: RAW (read-after-write), WAR, RAR, or WAW
Examples with operation ordering
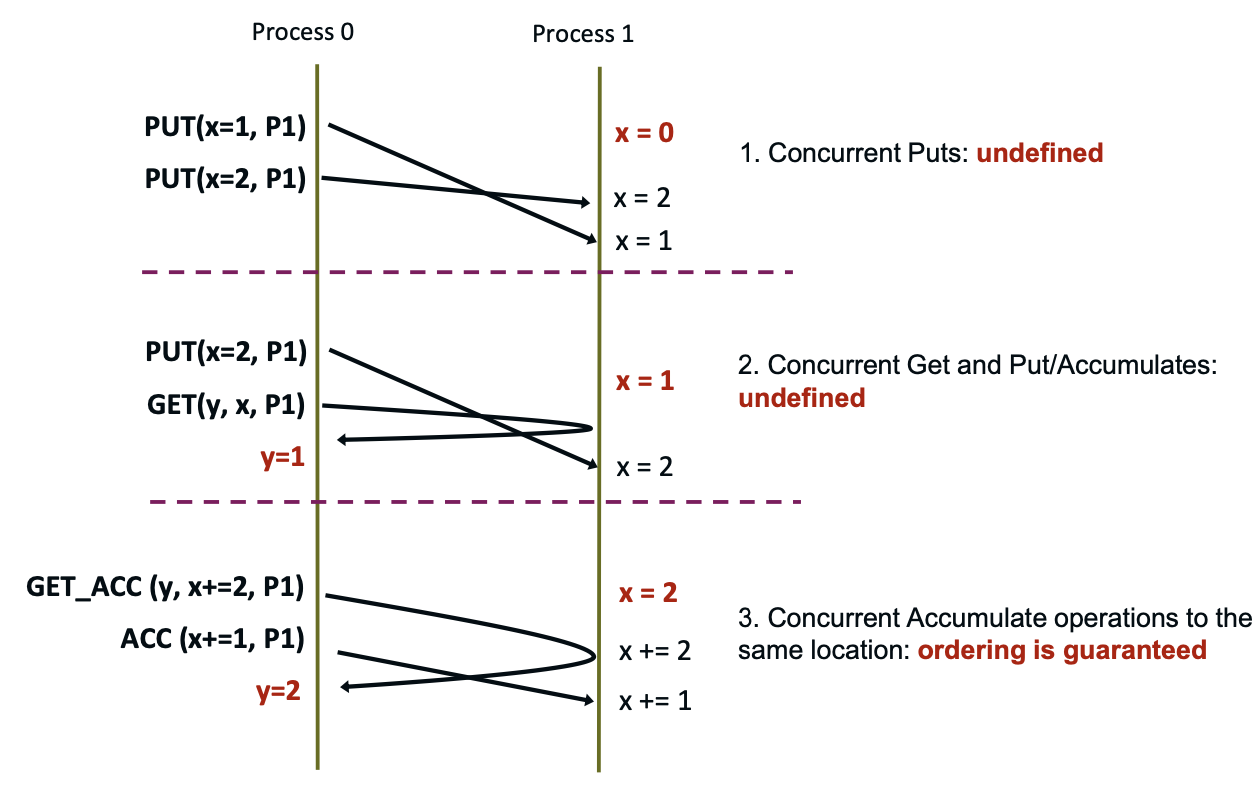
RMA Synchronization Models
RMA data access model:
- When is a process allowed to read/write remotely accessible memory?
- When is data written by process X is available for process Y to read?
During an exposure epoch:
- You should not perform local accesses to the memory window.
- Only one remote process can issue
MPI_Put.- There can be multiple
MPI_Accumulatefunction calls.
RMA synchronization models define these semantics
- 3 synchronization models provided by MPI:
- Fence (active target)
- Post-start-complete-wait (generalized active target)
- Lock/Unlock (passive target)
Data accesses occur within “epochs”
- Access epochs (called by origin process):
- contain a set of operations issued by an origin process
- there can be multiple access epochs within the same exposure epoch
- Exposure epochs (called by target process):
- enable remote processes to update a target’s window
- target process makes known to potential origin processes the availability of its memory window
Epochs define ordering and completion semantics
- Synchronization models provide mechanisms for establishing epochs
- e.g., starting, ending, and synchronizing epochs
Fence: Active Target Synchronization
MPI_Win_fence(int assert, MPI_Win win)
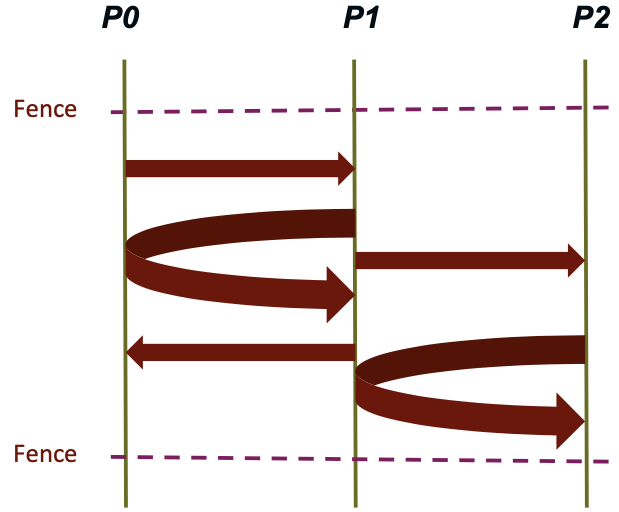
Collective synchronization model
- Starts and ends access and exposure epochs on all processes in the window
- All processes in group of “win” do an
MPI_WIN_FENCEto open an epoch - Everyone can issue PUT/GET operations to read/write data
- Everyone does an
MPI_WIN_FENCEto close the epoch - All operations complete at the second fence synchronization
PSCW: Generalized Active Target Synchronization
PSCW: Post-Start-Complete-Wait
1
2
MPI_Win_post/start(MPI_Group grp, int assert, MPI_Win win)
MPI_Win_complete/wait(MPI_Win win)
- Like FENCE, but origin and target specify who they communicate with
- Target: Exposure epoch
- Opened with
MPI_Win_post - Closed by
MPI_Win_wait
- Opened with
- Origin: Access epoch
- Opened with
MPI_Win_start - Closed by
MPI_Win_complete
- Opened with
- All synchronization operations may block, to enforce P-S/C-W ordering
- Processes can be both origins and targets
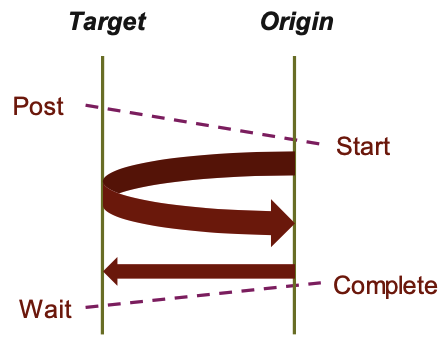
Lock/Unlock: Passive Target Synchronization
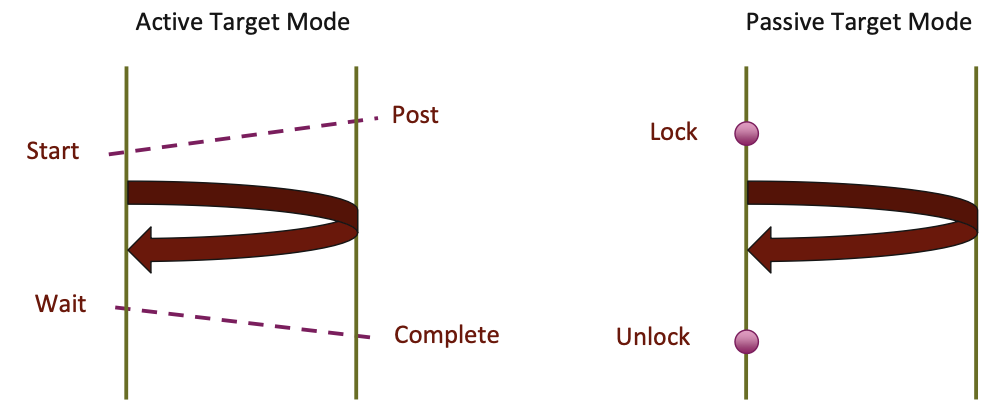
Passive mode: One-sided, asynchronous communication
- Target does not participate explicitly in communication operation
- Shared memory-like model
- (in the sense that the operations are all called on the origin process, with no synchronization routines called on the target process)
- Lock is an unfortunate choice of name - not a mutual exclusion; more a begin/end of RMA operations
1
2
3
MPI_Win_lock(int locktype, int rank, int assert, MPI_Win win)
MPI_Win_unlock(int rank, MPI_Win win)
MPI_Win_flush/flush_local(int rank, MPI_Win win)
Lock/Unlock: Begin/end passive mode epoch
- Target process does not make a corresponding MPI call
- Can initiate multiple passive target epochs to different processes
- Concurrent epochs to same process not allowed (affects threads)
Lock type:
- SHARED: Other processes using shared can access concurrently
- EXCLUSIVE: No other processes can access concurrently
Flush: remotely complete RMA operations to the target process
- After completion, data can be read by target process or a different process
Flush_local: locally complete RMA operations to the target process
Advanced Passive Target Synchronization
1
2
3
4
MPI_Win_lock_all(int assert, MPI_Win win)
MPI_Win_unlock_all(MPI_Win win)
MPI_Win_flush_all(MPI_Win win)
MPI_Win_flush_local_all(MPI_Win win)
Lock_all: Shared lock, passive target epoch to all other processes- Expected usage is long-lived:
lock_all,put/get,flush, …,unlock_all
- Expected usage is long-lived:
Flush_all- remotely complete RMA operations to all processesFlush_local_all- locally complete RMA operations to all processes
Which synchronization mode should I use, when?
- RMA communication has low overheads versus
send/recv- Two-sided: Matching, queuing, buffering, unexpected receives, etc…
- One-sided: No matching, no buffering, always ready to receive
- Utilize
RDMAprovided by high-speed interconnects (e.g. InfiniBand)
- Active mode: bulk synchronization
- e.g. ghost cell exchange
- Passive mode: asynchronous data movement
- Useful when dataset is large, requiring memory of multiple nodes
- Also, when data access and synchronization pattern is dynamic
- Common use case: distributed, shared arrays
- Passive target locking mode
- Lock/unlock - Useful when exclusive epochs are needed
- Lock_all/unlock_all- Useful when only shared epochs are needed
Assignment
- Write an MPI program which sends data in a “ring” among all P processes, i.e., rank i sends to (i+1)%P, which forwards the received data to (i+2)%P, etc.
- Compare the performance of two- and one-sided comm operations