CUDA
GPU Hardware Model
GPUs devote more hardware to computations, not as general-purpose as a CPU
- Optimized for parallelism (low depth workloads)
- Used as an accelerator to a host system
- They are compute units which maximize throughput
A GPU is built from Streaming Multiprocessors (SMs). It has a scalable caching mechanism (not all coherent!).
Communication with host system happens via PCIe bus or NVLINK.
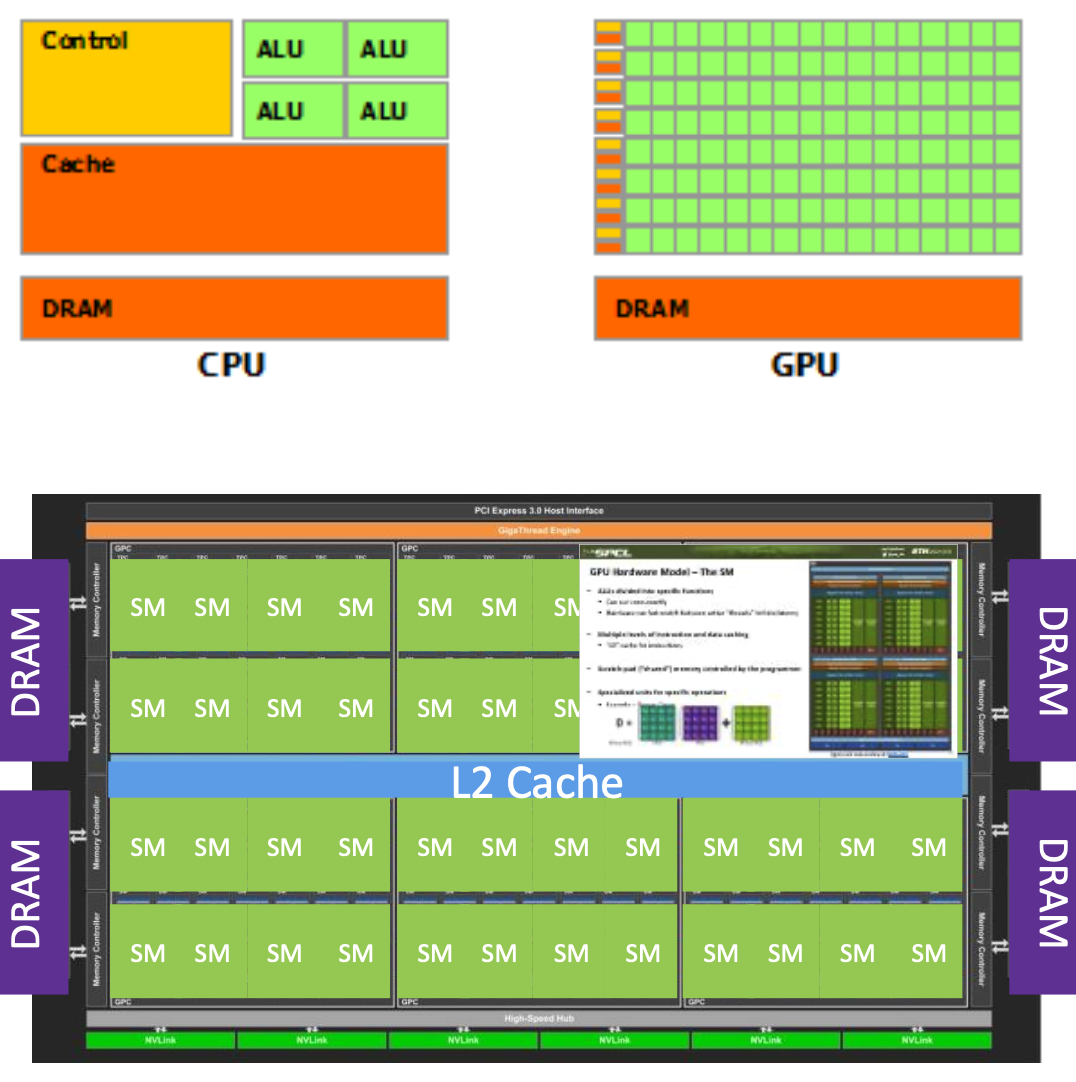
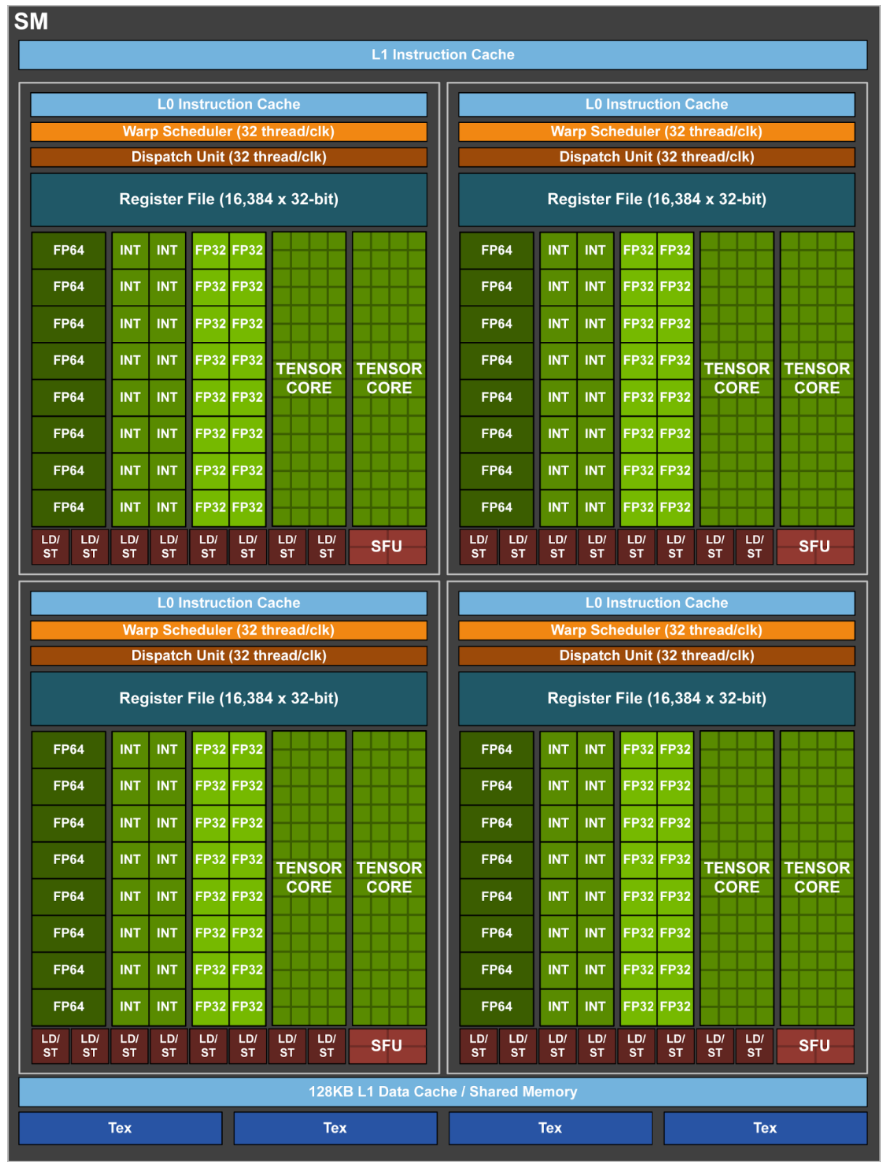
The Streaming Multiprocessors
ALUs are divided into specific functions.
- They can run concurrently
- Hardware can fast-switch between active “threads” to hide latency
Multiple levels of instruction and data caching
L0cache for instructions
Scratch-pad (“shared”) memory controlled by the programmer.
There are specialized units for specific operations:
- Tensor Cores:
GPU Programming Model – Memory
Memory explicitly allocated on the GPU
- “Managed” memory exists, but slower
Data copied from host to the GPU explicitly
Optimization: pinned memory
- Accelerates later memory copies, enables asynchronous copies
Question: Are memory writes to pinned memory visible to the GPU’s async
memcpy?
- Answer: Not necessarily without fences and the
volatilekeyword- pinning is an OS concept and does not impact the memory model
GPU Programming Model – Execution
GPU-compiled functions written separately from host code
- Both can coexist in
.cufiles, no GPU code in.c/.cppfiles
NVIDIA CUDA is (mostly) compatible with C++14.
Code is asynchronously executed.
- Streams act as “command queues” to the GPU
- Events can be queued onto the stream for synchronization
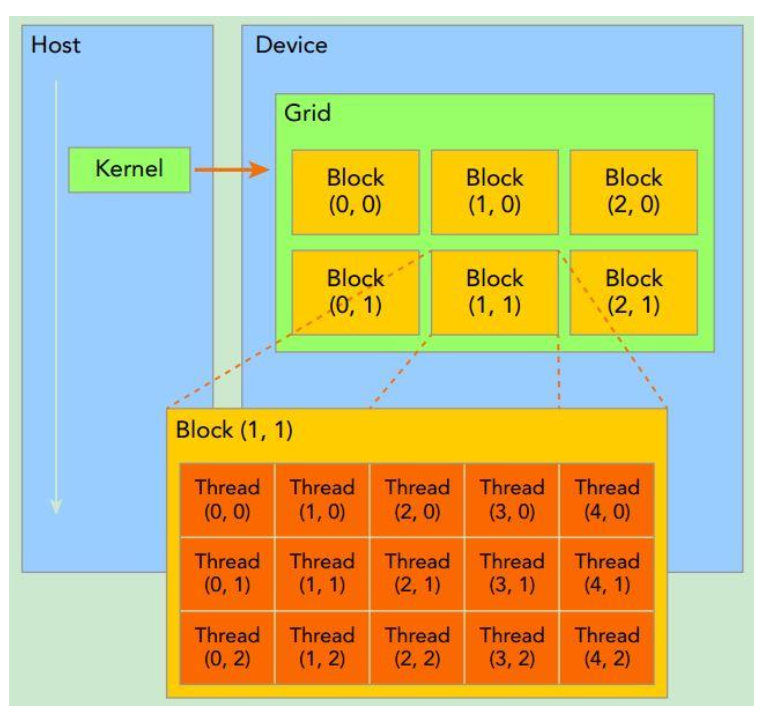
Threads execute “together” and are arranged in blocks
Invocation:
func<<numBlocks, threadsPerBlock>>Example:
Threads and blocks
A group of threads is called “block”
- Maximum $1024$ threads per block
- A block executes on one SM
- threads share registers
- One SM can run multiple blocks (if they fit)
- All threads in the same block have access to a shared memory
- but not across blocks!
- For your convenience, thread and block ids can be 1-, 2-, or 3-dimensional
Threads and blocks live on a logical 3D grid:
threadIdx.{x,y,z}– coordinate of calling threadblockDim.{x,y,z}– dimension of thread blockblockIdx.{x,y,z}– grid of blocks
Launch parameters (func<<numBlocks, threadsPerBlock>>) can be 3D specifications!
- Type “dim3”
Single Instruction, Multiple Threads (SIMT)
A warp keeps a single PC and stack and it’s composed of $32$ threads
Thread-blocks are composed of multiple warps
- Always execute on the same SM
Warps execute the same instruction, but on different data
- Same logical register maps to different physical register
- Uses prediction for instruction divergence
Warp divergence can cause $32$x slowdown (and more).
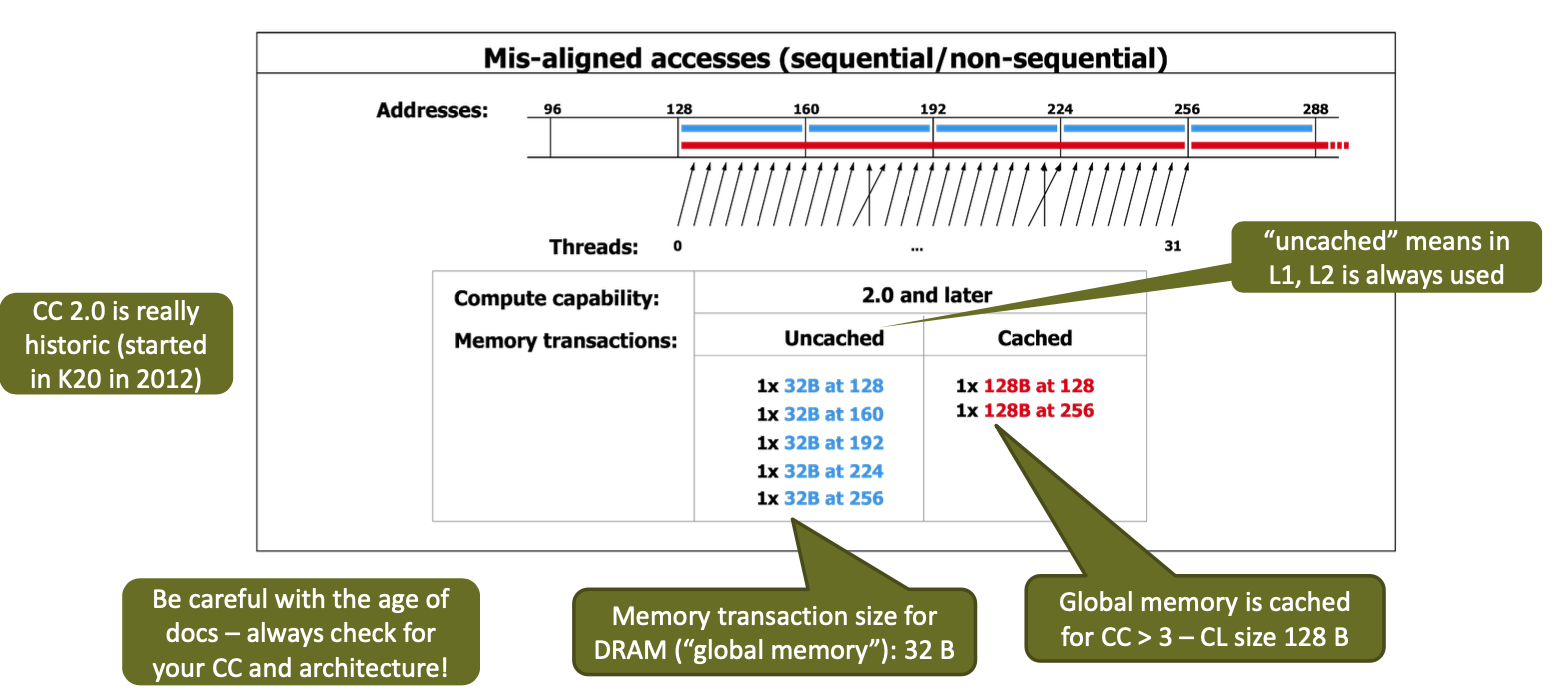
Memory Coalescing
Memory accesses of aligned elements (e.g., LDG.<X>) can be shared across threads in a warp
Accelerator programming with CUDA
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#define N 10
__global__ void add(int *a, int *b, int *c) {
int tid = blockIdx.x; // handle the data at this index
if (tid < N)
c[tid] = a[tid] + b[tid];
}
int main(){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// allocate the memory on the GPU
cudaMalloc((void**)&dev_a, N*sizeof(int));
cudaMalloc((void**)&dev_b, N*sizeof(int));
cudaMalloc((void**)&dev_c, N*sizeof(int));
// fill the arrays 'a' and 'b' on the CPU
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * i;
}
// copy the arrays to che GPU
cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
add<<<N,1>>>(dev_a, dev_b, dev_c);
// copy the array 'c' back from the GPU to the CPU
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
// free memory allocated on GPU
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
}
Workflow
- Copy input data from CPU memory to GPU memory
- Load GPU program and execute, caching data on chip for performance
- Copy results from GPU memory to CPU memory
Allocating Memory
Host and Device memory are separate!!
- You are familiar with host memory management in C:
malloc()andfree().
- On the GPU:
cudaMalloc()/cudaFree()/cudaMemcpy()- (different args/ret-values to malloc/free!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
__global__ void vec_add(int* a, int* b, int* c) {
*c = *a + *b;
}
int main(){
int* a, * b, * c;
int* a_d, * b_d, * c_d;
int size = 1 * sizeof(int);
// prepare data on the host
a = (int*)malloc(size);
b = (int*)malloc(size);
c = (int*)malloc(size);
*a = 42; *b = 23;
// allocate memory on the device
cudaMalloc((void**)&a_d, size);
cudaMalloc((void**)&b_d, size);
cudaMalloc((void**)&c_d, size);
// copy data from host to device
cudaMemcpy(a_d, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, b, size, cudaMemcpyHostToDevice);
// launch kernel
vec_add<<<1,1>>>(a_d, b_d, c_d);
// copy result from device to host
cudaMemcpy(c, c_d, size, cudaMemcpyDeviceToHost);
cudaFree(a_d); cudaFree(b_d); cudaFree(c_d);
validate(a, b, c);
free(a); free(b); free(c);
}
Example
Vec_add using N blocks
- Can launch kernel using
<<<N,1>>>so we useNblocks with1thread each - Can access block ID using
blockIdx.x(usey,zif grid was declared as 2- or 3-dimensional)
1
2
3
4
5
6
7
8
9
10
11
12
__global__ void vec_add(int* a, int* b, int* c) {
if (blockIdx.x < N)
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
int main(){
// ...
cudaMemcpy(a_d, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(b_d, b, N * sizeof(int), cudaMemcpyHostToDevice);
vec_add<<<N,1>>>(a_d, b_d, c_d);
// ...
}
Vec_add using N threads
- Can launch kernel using
<<<1,N>>>so we useNthreads within1block - Can access thread ID using
threadIdx.x(usey,zif block was declared as 2- or 3-dimensional) - Can access block size using
blockDim.x
Combining threads and blocks
All threads in a block “compete” for registers!
- Using the maximum ($1024$) number of threads per block might not be a good idea if you use a lot of local variables!
- Threads within a block can communicate using (fast) shared memory.
- How can we combine thread and block indexes?

Use built-in variable
blockDim.xto get number of threads per block.
Shared Memory between threads
Shared Memory can be declared (in kernel) using __shared__
- Only allocated once per block!
- Data is not visible to threads in other blocks!
Cache data in shared memory
- Read
(blockDim.x + 2 * radius)input elements from global memory to shared memory - Compute
blockDim.xoutput elements - Write
blockDim.xoutput elements to global memory
Each block needs a halo of radius elements at each boundary

1D Stencil Kernel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[BLOCK_SIZE + 2 * RADIUS];
// Global and local indices for the current thread
int gindex = threadIdx.x + blockIdx.x * blockDim.x;
int lindex = threadIdx.x + RADIUS; // Local index with an offset to access the halo region
// Read input elements into shared memory
temp[lindex] = in[gindex];
// Load additional elements into the halo region
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
// Synchronize (ensure all the data is available)
__syncthreads();
// Apply the stencil
int result = 0;
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset];
// Store the result
out[gindex] = result;
}
Race Condition on Shared Memory – __syncthreads()
After the data is in the temp array, how do we make sure threads are synchronized?
- Otherwise thread
RADIUS+1might read the halo before it is written - Can use
void __syncthreads();as a barrier for all threads in a block. - Be careful when using in conditional code!
Sometimes a global barrier is overkill
- Assume we have a large picture and want to create a histogram of its color values
- Each thread does something like
hist[color[index]] += 1
- In this case we can use
cudaAtomicAdd(&hist[color[index]], 1)- Also has other atomics, i.e.,
CAS - Also works on global memory
- Also has other atomics, i.e.,
Let’s write a matrix multiplication program
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
__global__ void matrixMul(float* a, float* b, float* c, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// iterate over row, and down column
c[row * N + col] = 0;
for (int k = 0; k < N; k++){
c[row * N + col] += a[row * N + k] * b[k * N + col];
}
}
int main(){
int N = 1024;
size_t bytes = N * N * sizeof(float);
float *d_a, *d_b, *d_c;
float *h_a, *h_b, *h_c;
h_a = (float*)malloc(bytes);
h_b = (float*)malloc(bytes);
h_c = (float*)malloc(bytes);
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice);
int THREADS = 32;
int BLOCKS = N / THREADS; // assume N is divisible by THREADS
dim3 threads(THREADS, THREADS);
dim3 blocks(BLOCKS, BLOCKS);
matrixMul<<<blocks, threads>>>(d_a, d_b, d_c, N);
cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost);
verify_result(h_a, h_b, h_c, N);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
free(h_a); free(h_b); free(h_c);
return 0;
}
To improve performance, use local registers (variables) inside kernel functions.
- Declare a
float tmp = 0variable to accumulate the result- Only write back to the
cmatrix at the end!
Asynchronous Memcpy

Synchronous vs Asynchronous Memcpy
cudaMemcpy()blocks until the transfer is completecudaMemcpy()only starts when all previous API calls in the same stream have completed- Kernel launches return immediately
- We need a way to do asynchronous copies!
cudaMemcpyAsync()– returns immediately
- Use multiple concurrent streams instead of the implicit default stream
What is needed to use cudaStreams?
- Host memory must be pinned, not pageable – instead of allocating with
malloc, allocate withcudaMallocHost(**ptr, size) - Create stream with
cudaStream_t stream; cudaStreamCreate(&stream); - Add stream as last param to
cudaMemcpyAsync()and kernel launch cudaStreamSynchronize(stream)waits for all calls in streamcudaDeviceSynchronize()syncs all streams
Streams example - Setup
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main(void){
const int streamsNum = 2;
int N = 1 << 10; // 1024 elements
float *h_a == NULL, *h_b = NULL;
cudaMallocHost((void**)&h_a, N * sizeof(float));
cudaMallocHost((void**)&h_b, N * sizeof(float));
for (int i = 0; i < N; i++) {
h_a[i] = 0;
h_b[i] = 0;
}
// device
float *d_a = NULL, *d_b = NULL;
cudaMalloc((void**)&d_a, N * sizeof(float));
cudaMalloc((void**)&d_b, N * sizeof(float));
// streams
cudaStream_t streams[streamsNum];
for (int i = 0; i < streamsNum; i++)
cudaStreamCreate(&streams[i]);
// ...
Streams example – Async operations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// ...
// h2d
cudaMemcpyAsync(d_a, h_a, N * sizeof(float), cudaMemcpyHostToDevice, streams[0]);
cudaMemcpyAsync(d_b, h_b, N * sizeof(float), cudaMemcpyHostToDevice, streams[1]);
// kernel
dim3 block = dim3(128,1,1);
dim3 grid = dim3((N + block.x - 1) / block.x, 1, 1);
testKernel <<< grid, block, 0, streams[0] >>> (d_a, N);
testKernel <<< grid, block, 0, streams[1] >>> (d_b, N);
// ...
Streams example - Validation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// ...
cudaDeviceSynchronize();
int error = 0;
for (int i = 0; i < N; i++) {
if (h_a[i] != N) error += 1;
if (h_b[i] != N) error += 1;
}
if error == 0:
printf("Success!\n");
else:
printf("Error: %d elements do not match!\n", error);
for (int i = 0; i < streamsNum; i++) {
cudaStreamDestroy(streams[i]);
}
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFree(d_a);
cudaFree(d_b);
return 0;
}
Unified Memory
CUDA also supports unified memory
- You allocate it using
cudaMallocManaged() - You can access it from the Host and the device!
It lowers the development effort. However, it’s harder to predict performance.
Unified Memory Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int main(void){
int N = 1 << 20; // 1M elements
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++){
x[i] = 1.0f;
y[i] = 2.0f;
}
// Launch kernel
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = max(maxError, abs(y[i]-3.0f));
printf("Max error: %f\n", maxError);
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
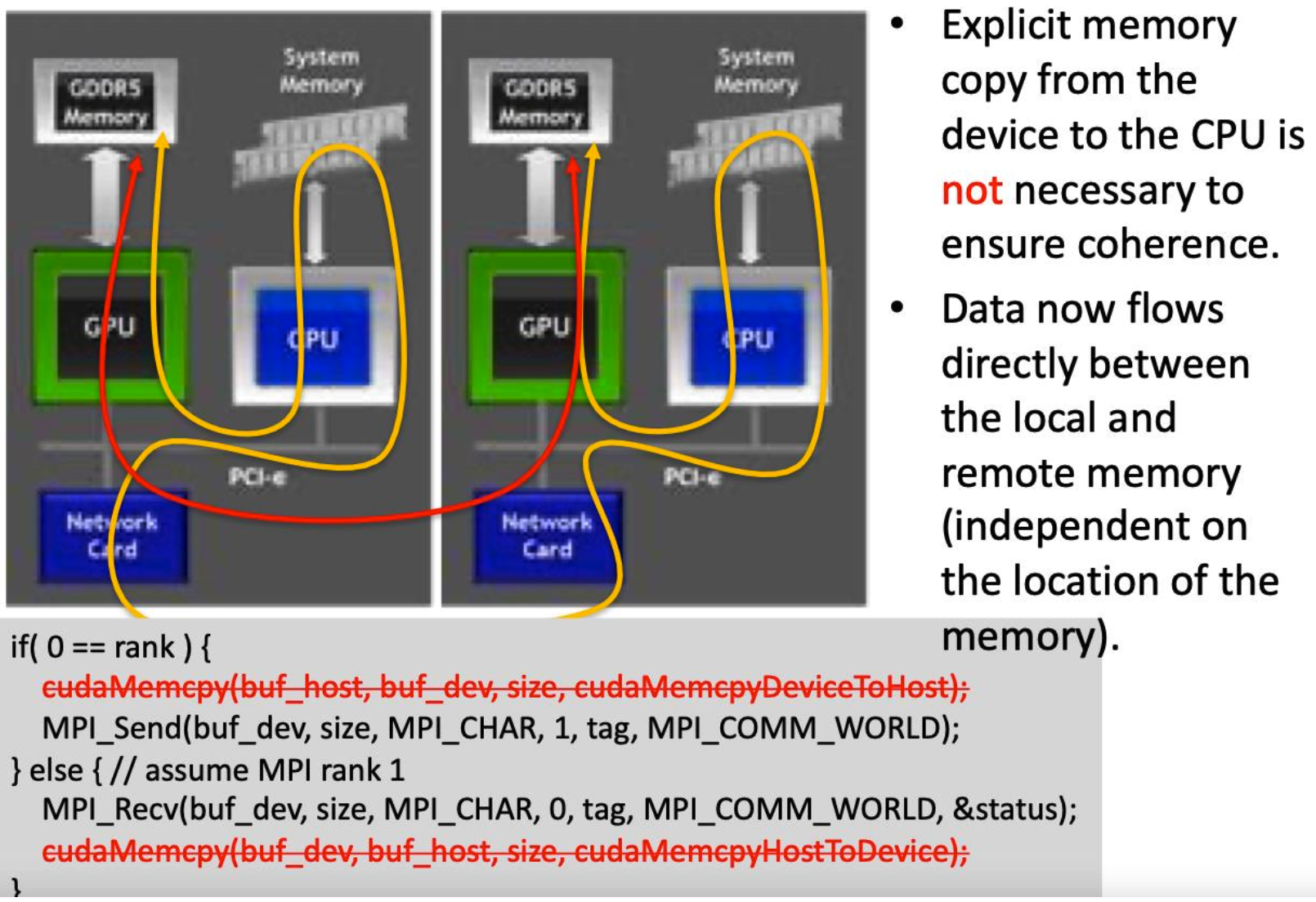
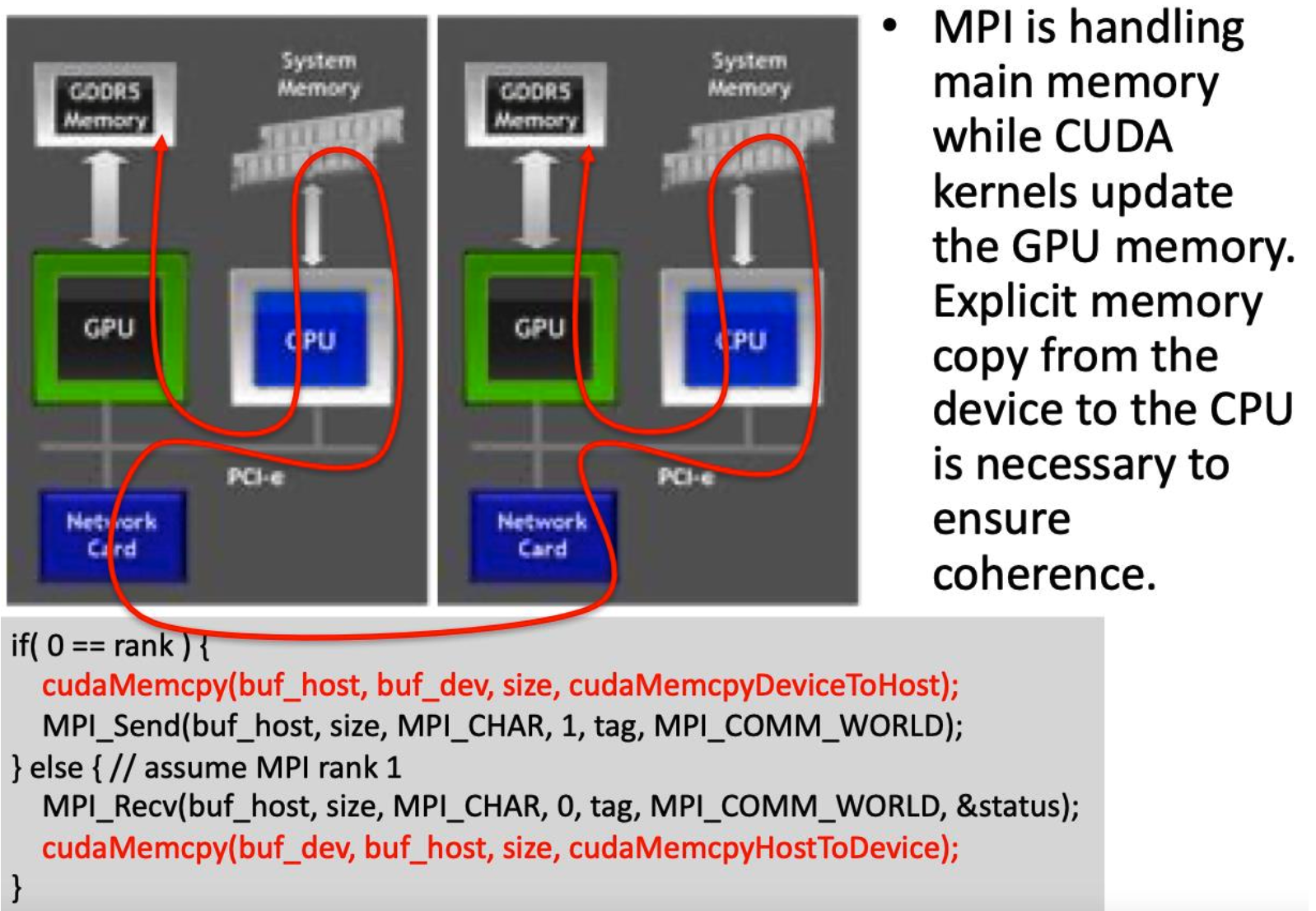
CUDA-Aware MPI
Most modern MPI implementations are CUDA aware
- Allow you to pass pointers to device memory to CUDA functions!
- Be mindful of needed synchronization
CUDA + MPI
CUDA-aware MPI