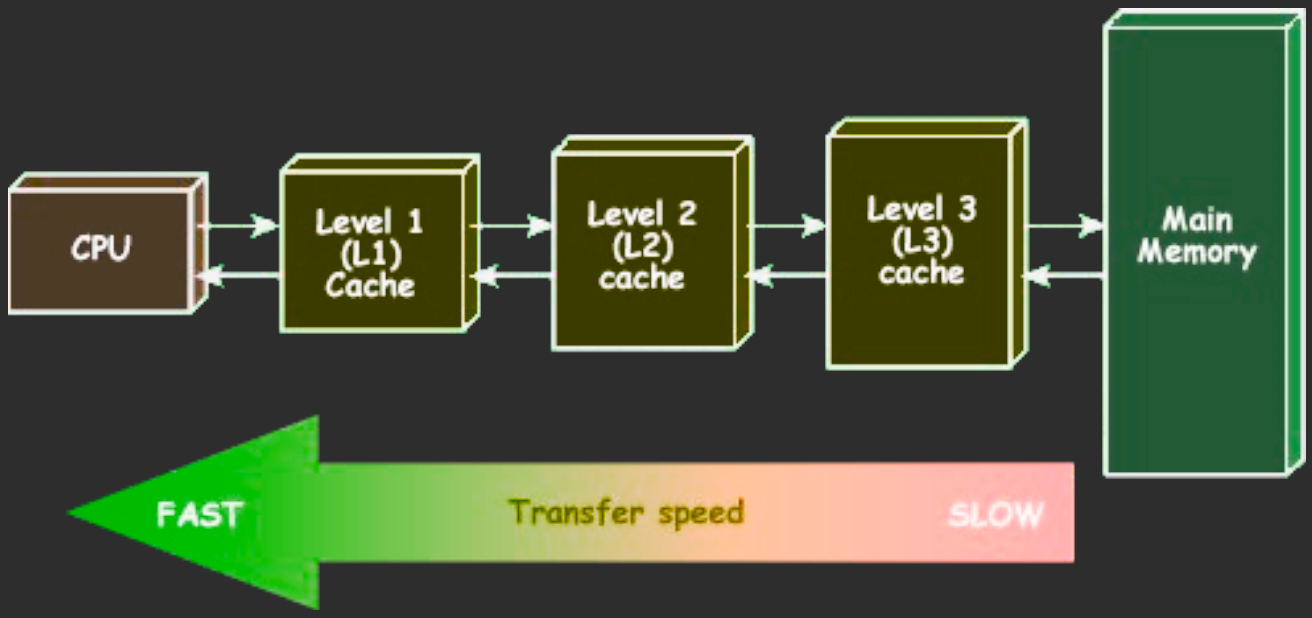
CPU Caches
Cache architecture in modern CPUs
Important properties of caches
1) Size, Transfer Size & Inclusivity
L1 (e.g, 32KB) < L2 (e.g., 256KB) < L3 (e.g., 8MB) = LLC Cache line size is often 64B. On ARM sometimes 128B.
2) L3 Inclusivity
- Inclusive (most x86 client CPUs)
- Exclusive (rare)
- Non-inclusive (ARM, most x86 server CPUs in the past few years)
3) Addressing
- Caches are divided in sets
- Each address can only go to its own set
- E.g. 8MB LLC on client
- Intel has 8192 sets
- (8MB / 64) / 8192 = 16
- Each set has 16 entries -> wayness
4) Replacement
Cache lookup:
- Present → Cache hit
- Not present → Cache miss → Replacement
Replacement policies are often derivatives of LRU, unless you are dealing with GPUs…
L1 is VIPT, 64 sets: bits 6-11 decide the set (shared between virtual and physical page) TLB lookup is done in parallel with physical tag transfers from the right set. Tag match? L1 hit, transfer the data.
L2 is PIPT, usually 1024 sets: bits 6-15 decide the set. L2 is always accessed after virtual address translation
L3 is sliced PIPT, usually 2048 sets per slice (each slice has 1 or 2 cores): bits 6-16 decide the set.
Some Observations on Intel CPUs
4KB page covers bits 0-11, overlapping with set bits on L1 and L2 If the first cache lines of two pages map to the same set S, then their second cache lines will map to the same set S’, and their third cache lines…
On L1, the first cache line of any page maps to the same set.
On L2, the first cache line of every other n-th physical page maps to the same set. – What is n?
On L3, the first cache line of (2MB/16 = 128KB) every other 32th physical page maps to the same set number, but may map to a different slice
If addresses A and B map to set/slice S1, then A XOR d and B XOR d map to set/slice S2
If first cache line of pages P1 and P2 share a set, then we know the sets for the other offsets (even if they map to different slices)
Eviction set building strategy
- Allocate a large pool of pages
- Pick a page P from the pool
- Check that accessing the first cacheline of all the other pages evicts the first cacheline of P
- Pick a page Q from the pool and remove it. See whether the (pool - Q) still evicts P. If so, then remove Q from the pool
- Keep removing pages until the pool has exactly 4 members. This is an eviction set for P
- Try this again with a page that the eviction set for P does not evict to find another eviction set
Flushing the cache: CLFLUSH and CLFLUSHOPT
- Flushes a memory location (code or data)
- Useful when attacker has access to the target memory location
CLFLUSHis ordered with otherCLFLUSHes regardless of the address.CLFLUSHOPTis the newer variant that is not ordered with otherCLFLUSHOPTs- ->(runs faster)
Cache attacks
Threat models
FLUSH+RELOAD requires the attacker to have access to the target code/data. When is this possible?
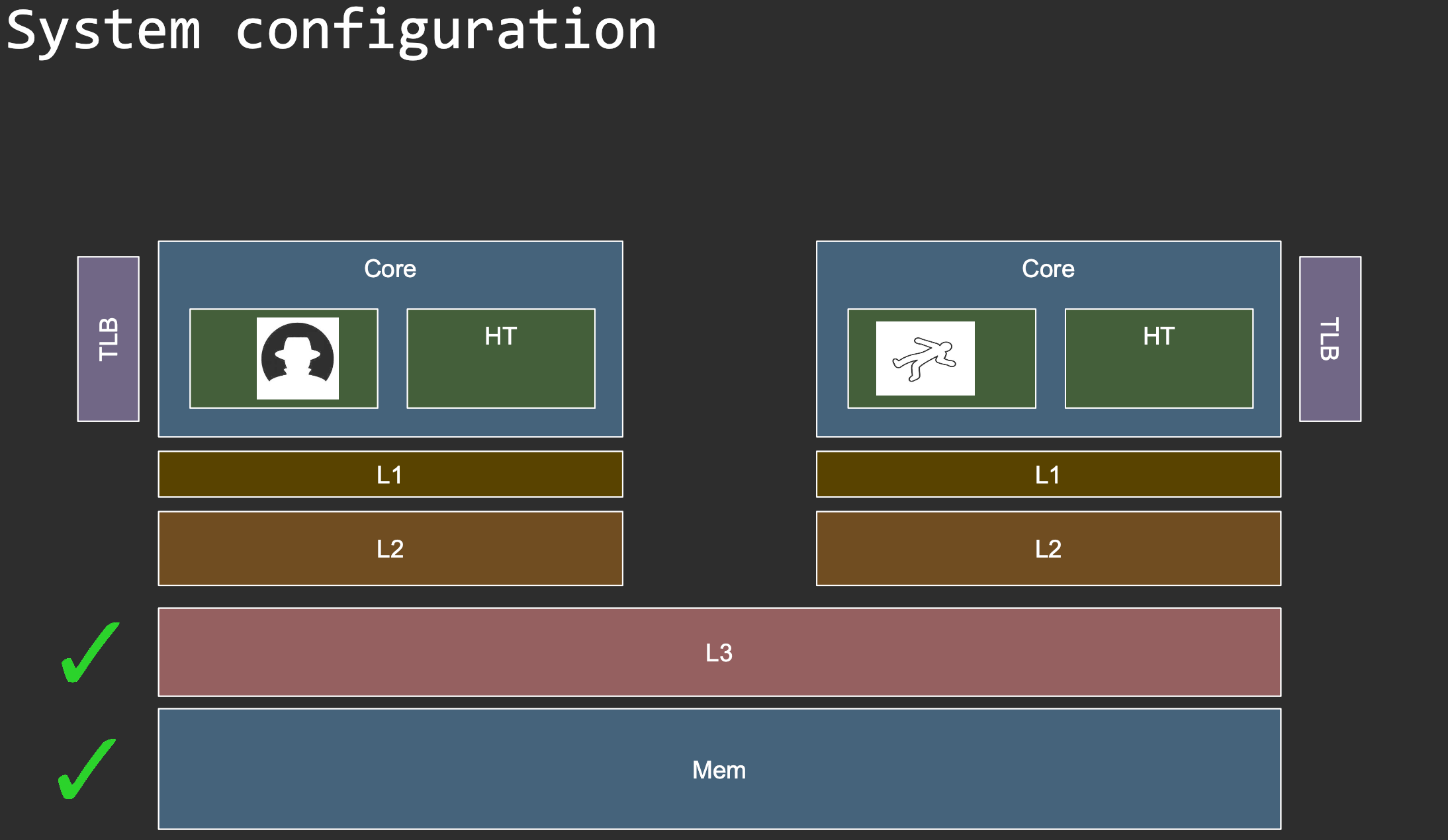
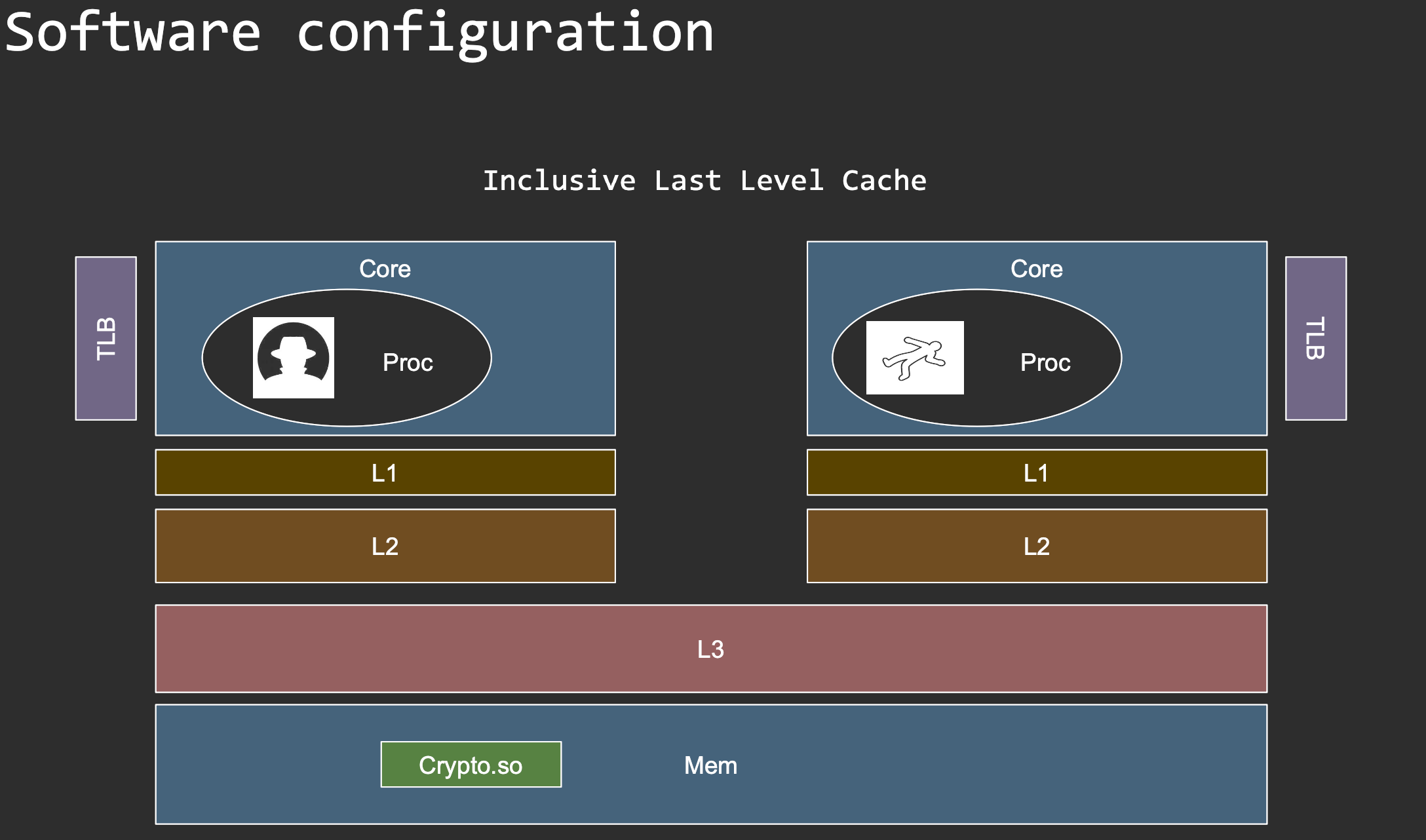
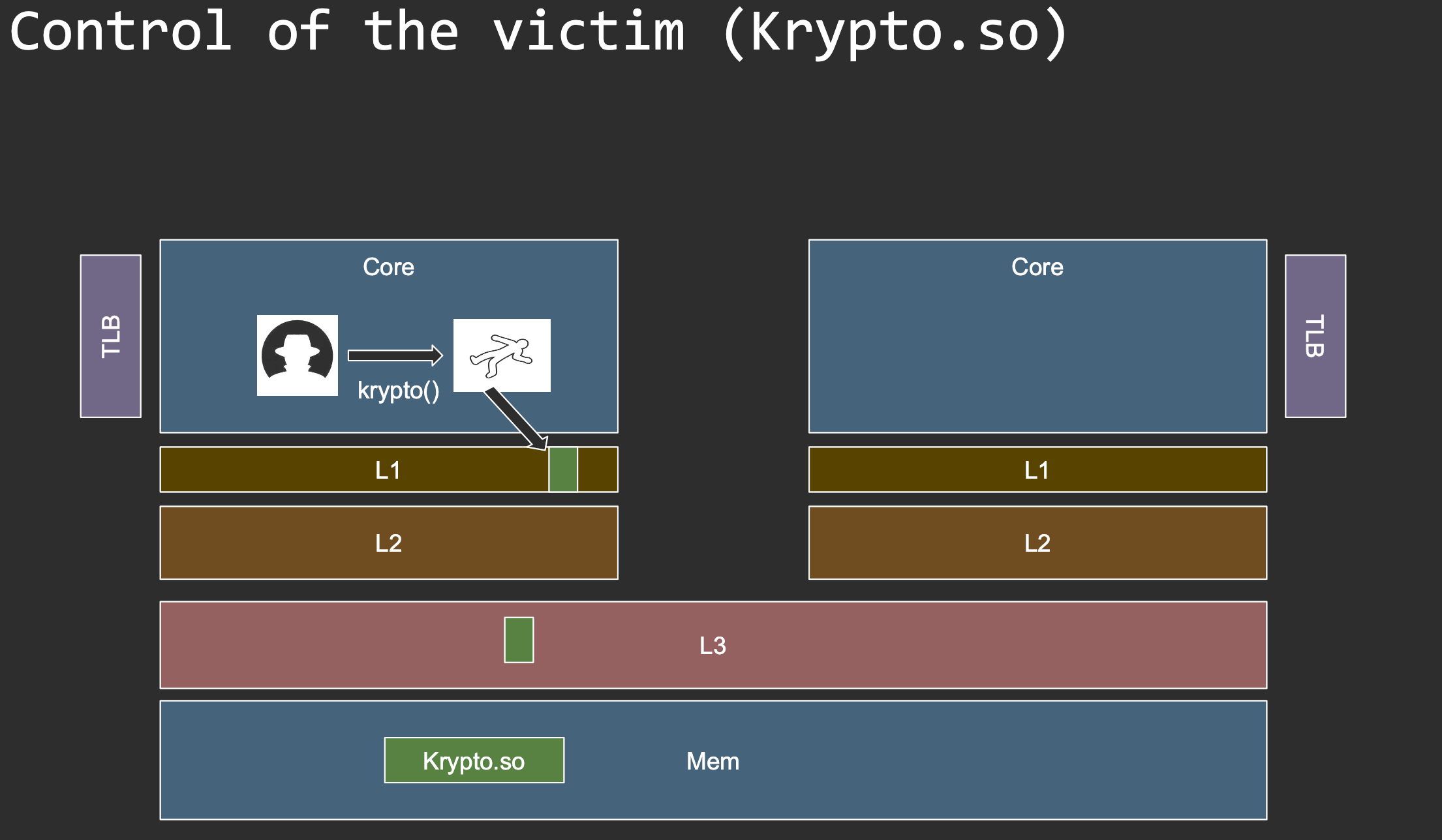
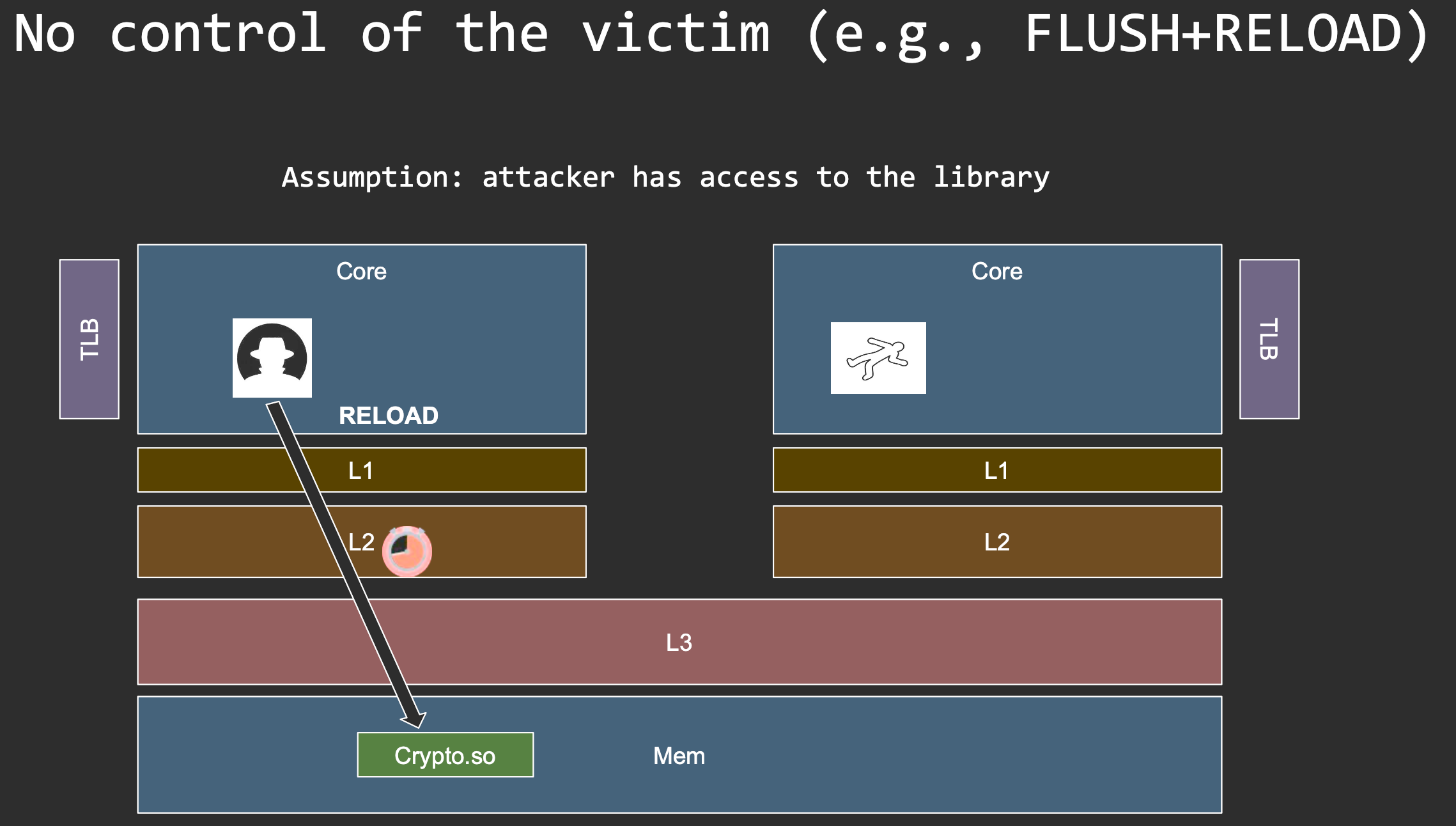
Goals
1) Kick out the victim’s cache line 2) Measure whether victim access happened
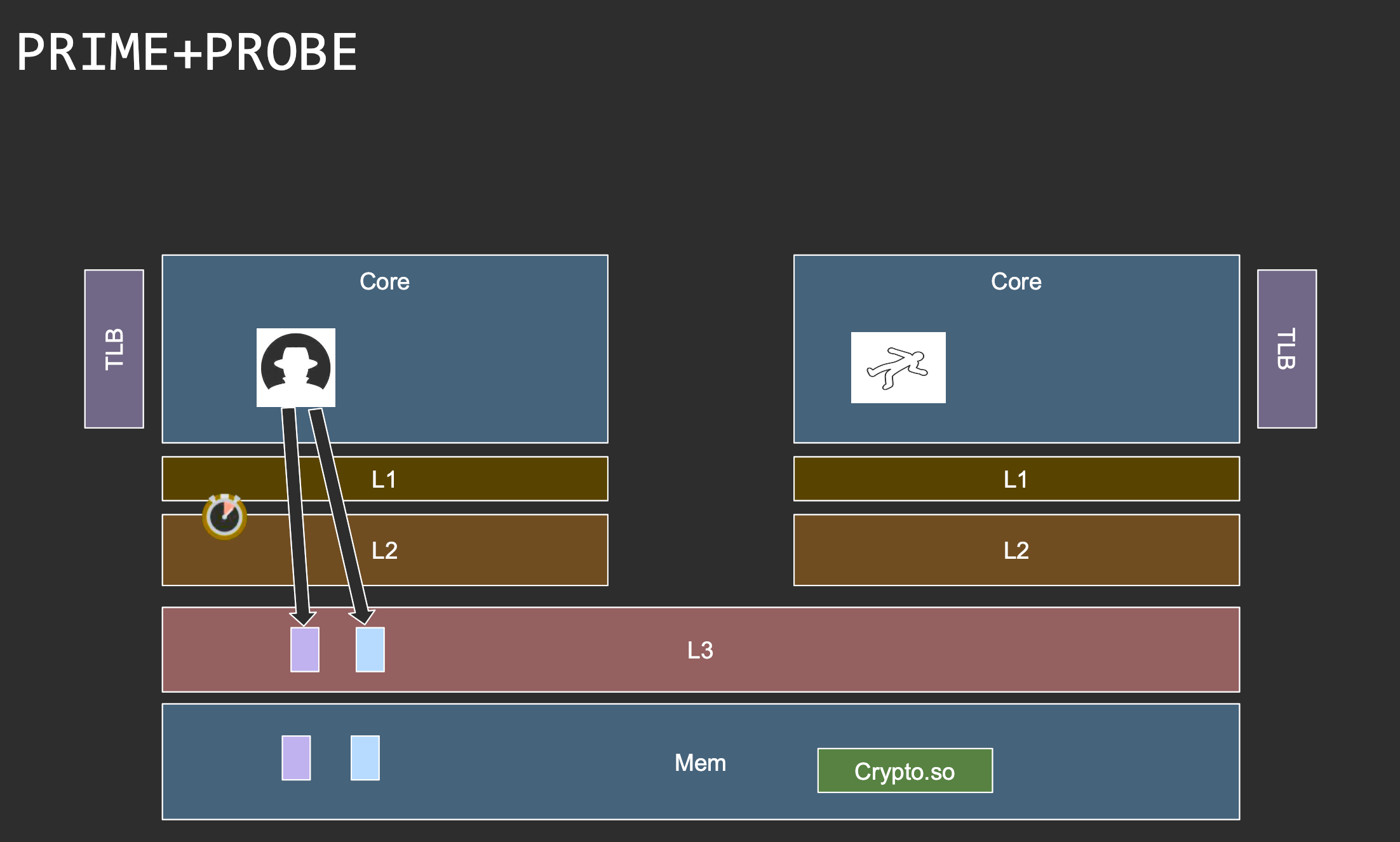
Eviction sets
Eviction sets are useful in two cases:
- if
CLFLUSHorCLFLUSHOPTare not available- e.g. in JavaScript or certain ARMs
- if attacker does not have access to the secret-dependant data/instruction directly
- e.g. virtual machines in the cloud
Eviction set: given a target cache set in {L1, L2, L3}, a set of memory addresses that if accessed, will kick out any other entry in that cache set
Address translation (virtual memory)
Address spaces:
- Virtualize physical memory
- Provide flexible memory management at page granularity
- Isolation and protection
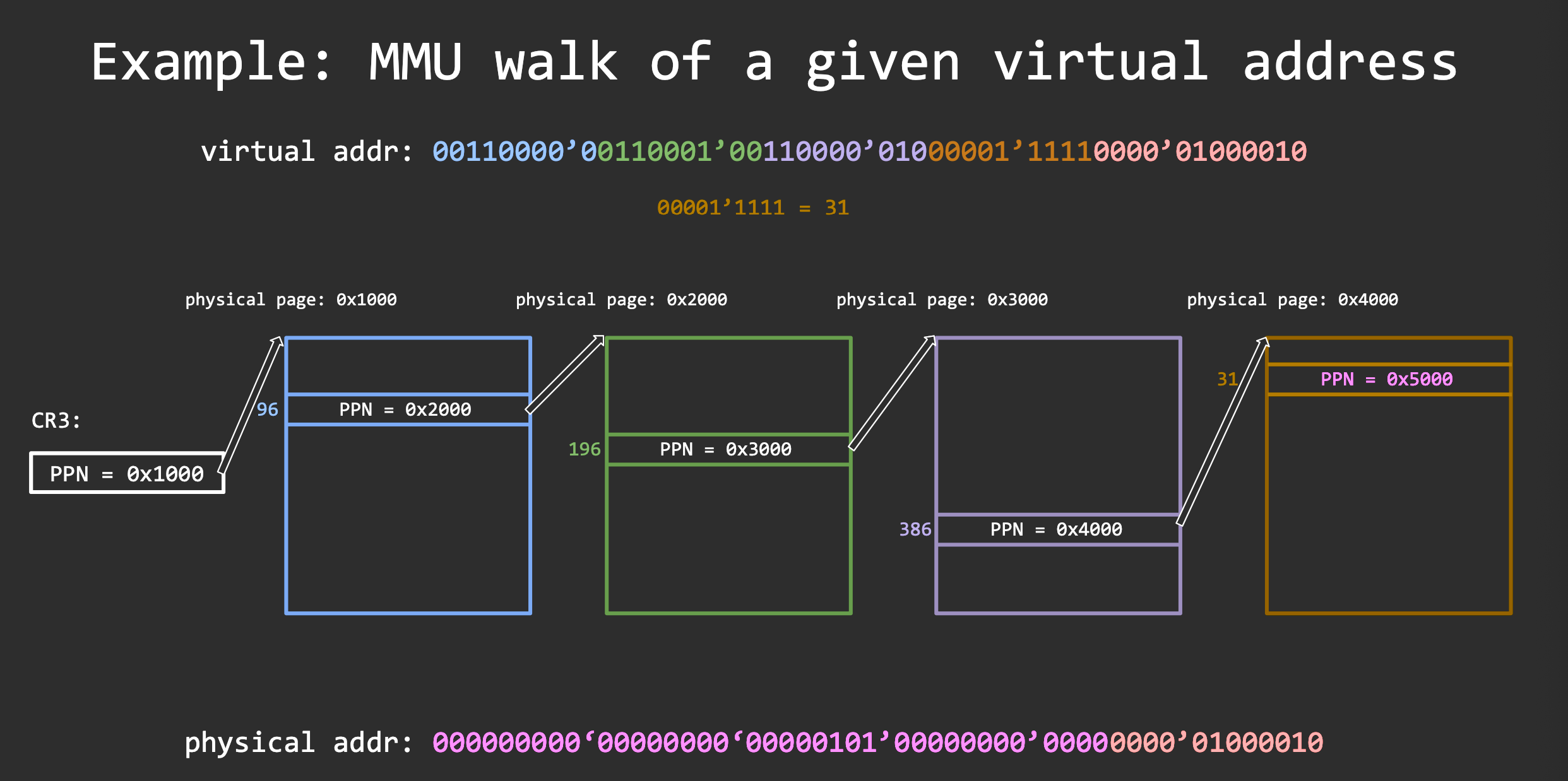
We need to program the CPU’s memory management unit (MMU) through page tables 
Translation caches - TLB
TLB scalability
- Memory has become plentiful
- Your browser uses gigabytes of memory
- Skylake TLB coverage with 4KB pages: 6MB = 1536
- (L2TLB) × 4KB
- And this gets even worse with more memory
How do you fix this?
- Caching page-table pages
- Bigger pages
- Translation caches
TLB is tagged with all bits of the virtual address. Translation caches are tagged with parts of the virtual address. The rest is followed by a partial page walk.
In x86_64:
- TLB: 36 bit tag
- Translation cache: 27 bit tag