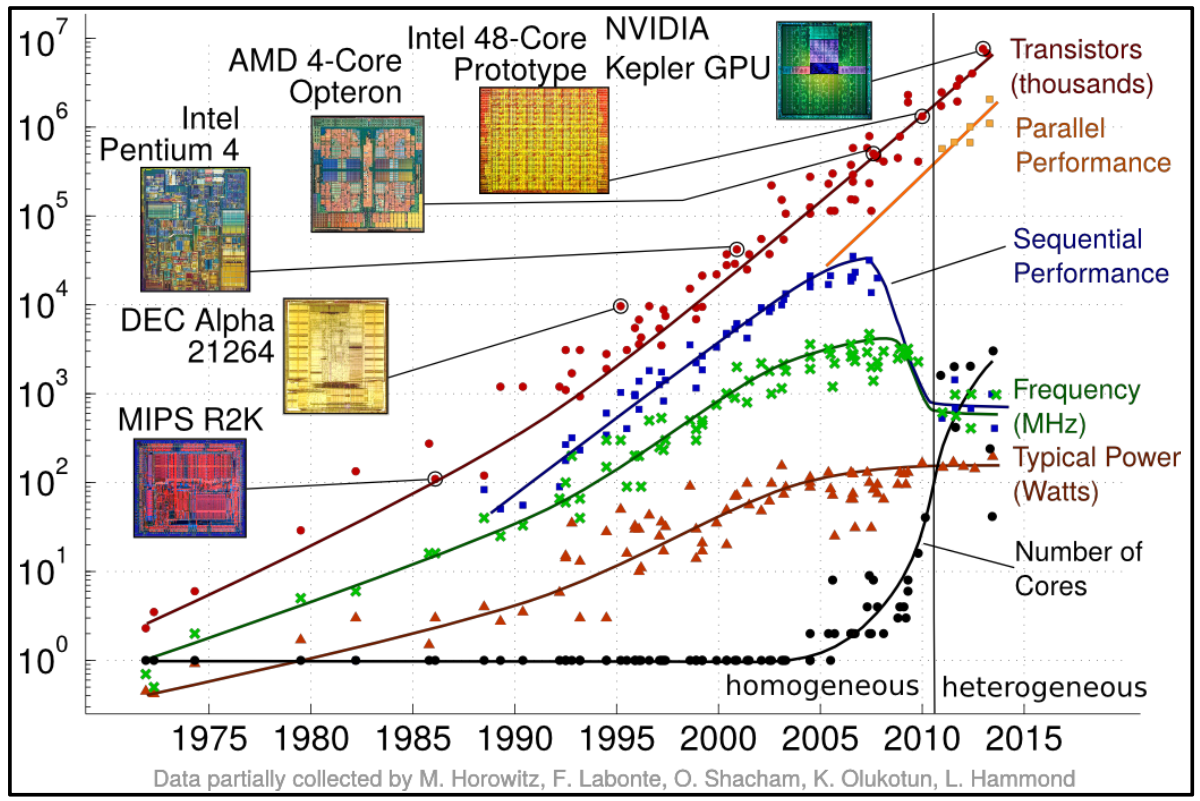
Intro to Parallel Architectures
Higher voltage is needed to drive higher frequency (due to fixed capacitance). Higher voltage also increases static power dissipation (leakage). 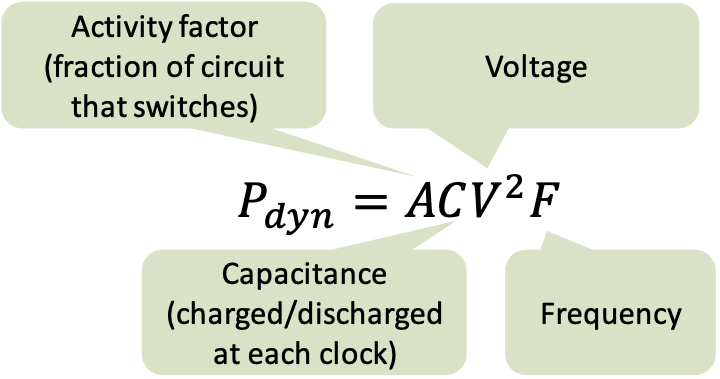
Low-Power Design Principles (2005)

Even if each simple core is $1/4$th as computationally efficient as complex core, you can fit hundreds of them on a single chip and still be 100x more power efficient. 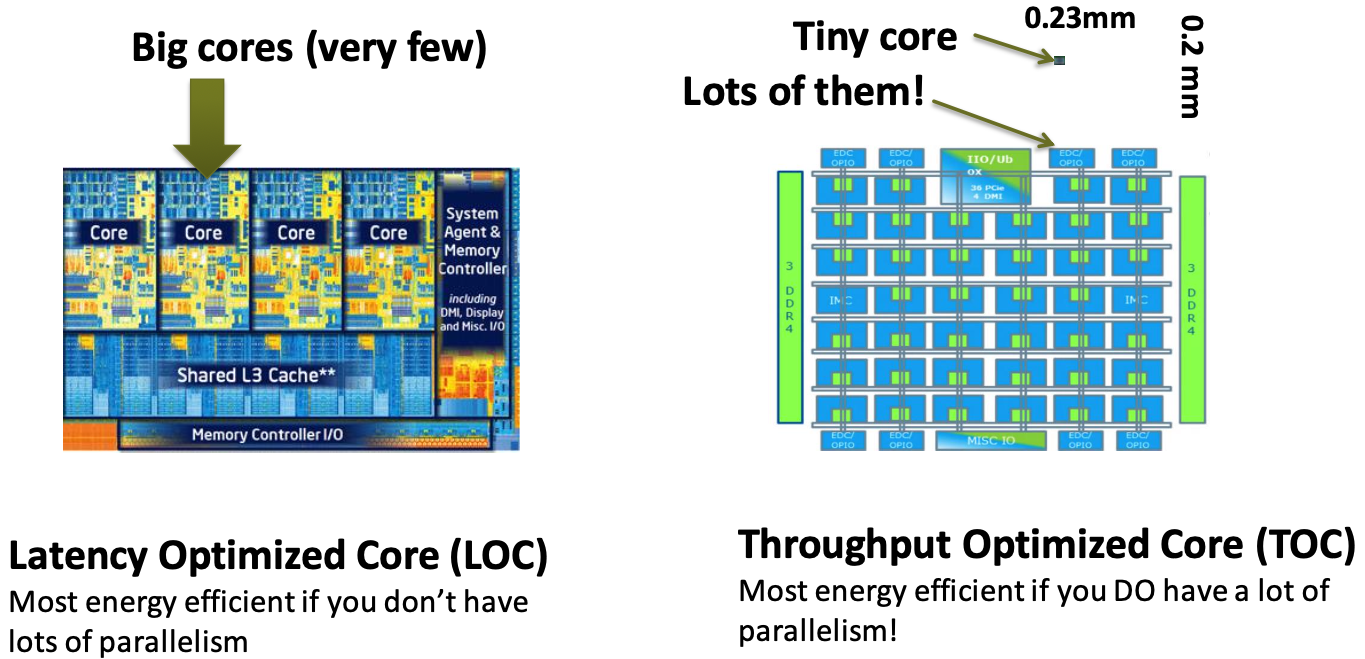
Data movement – the wires
Energy Efficiency of copper wire:
- $Power = Frequency * Length / cross-section-area$
- Wire efficiency does not improve as feature size shrinks
Energy Efficiency of a Transistor:
- $Power = V^2 * frequency * Capacitance$
- Capacitance ~= Area of Transistor
- Transistor efficiency improves as you shrink it
Net result is that moving data on wires is starting to cost more energy than computing on said data
Pin Limits – cf. Rent’s rule
Moore’s law doesn’t apply to adding pins to package
- $30\%$ + per year nominal Moore’s Law
- Pins grow at $~1.5-3\%$ per year at best
$4000$ Pins is aggressive pin package
- Half of those would need to be for power and ground
- Of the remaining $2k$ pins, run as differential pairs
- Beyond 15Gbps per pin power/complexity costs hurt!
10Gpbs * 1kpins is~1.2TB/sec
$2.5$D Integration gets boost in pin density
- But it’s a $1$ time boost (how much headroom?)
- $4$TB/sec? (maybe $8$TB/s with single wire signalling?)
Shared Memory Machine Abstractions
Any Processing Element (PE) can access all memory
- Any I/O can access all memory (maybe limited)
OS (resource management) can run on any PE
- Can run multiple threads in shared memory
- Used for $40$+ years
Communication through shared memory
- Load/store commands to memory controller
- Communication is implicit
- Requires coordination
Coordination through shared memory
- Complex topic
- Memory models
Shared Memory Machine Programming
Threads or processes
- Communication through memory
Synchronization through memory or OS objects
- Lock/mutex (protect critical region)
- Semaphore (generalization of mutex (binary sem.))
- Barrier (synchronize a group of activities)
- Atomic Operations (CAS, Fetch-and-add)
- Transactional Memory (execute regions atomically)
Practical Models:
Posixthreads (ugs, will see later)MPI-3OpenMP- Others:
Java Threads
Distributed Memory Machine Programming
Explicit communication between PEs
- Message passing or channels
Only local memory access, no direct access to remote memory
- No shared resources (well, the network)
- Less correctness issues – but now needs to think about data distribution
Programming model: Message Passing (MPI)
- Communication through messages or group operations (broadcast, reduce, etc.)
- Synchronization through messages (sometimes unwanted side effect) or group operations (barrier)
- Typically supports message matching and communication contexts
DMM Example: Message Passing
- Send specifies buffer to be transmitted
- Recv specifies buffer to receive into
- Implies copy operation between named PEs
- Optional tag matching
- Pair-wise synchronization (cf. happens before)
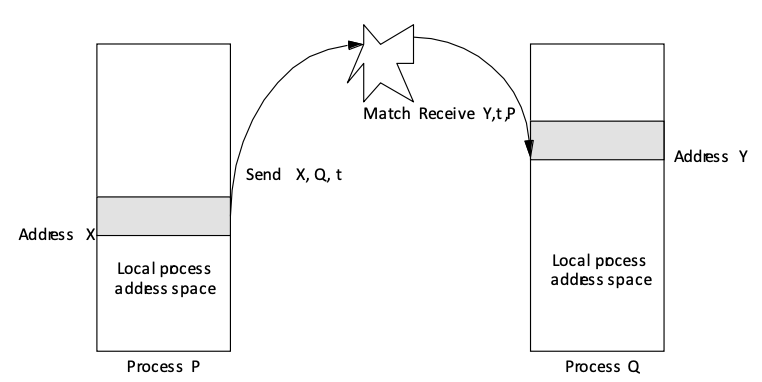
DMM MPI Compute Pi Example

DMM Example: Partitioned Global Address Space
Shared memory emulation for DMM: Usually non-coherent Distributed Shared Memory: Usually coherent PGAS Simplifies shared access to distributed data
- Has similar problems as SMM programming
- Sometimes lacks performance transparency
OpenMP
What is it? A set of compiler directives and a runtime library, with the goal of simplifying (and standardizing) how multi-threaded application are written. 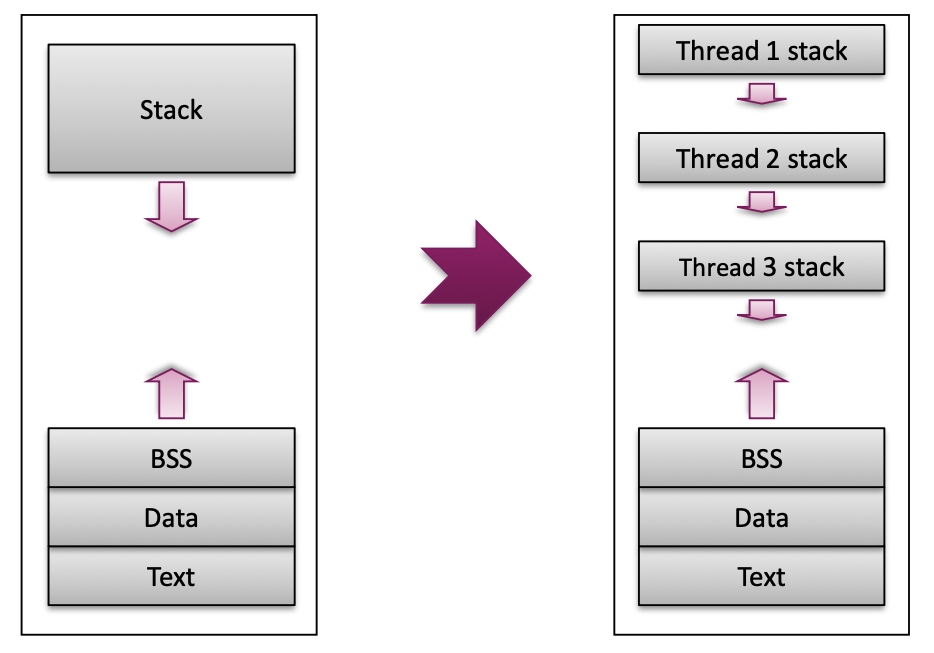 OpenMP is based on Fork/Join model
OpenMP is based on Fork/Join model
- When program starts, one Master thread is created
- Master thread executes sequential portions of the program
- At the beginning of parallel region, master thread forks new threads
- All the threads together now forms a “team”
- At the end of the parallel region, the forked threads die
What’s a Shared-Memory Program?
One process that spawns multiple threads
- Threads can communicate via shared memory
- Read/Write to shared variables
- synchronization can be required!
- OS decides how to schedule threads

Parallel Regions
A parallel region identifies a portion of code that can be executed by different threads
- You can create a parallel region with the
paralleldirective - You can request a specific number of threads with
omp_set_num_threads(N) - Each thread will call
p(ID,A)with a different value ofID - All the threads execute the same code
- The
Aarray is shared - Implicit synchronization at the end of the parallel region

Behind the scenes
- The OpenMP compiler generates code logically analogous to that on the right
- All known OpenMP implementations use a thread pool so full cost of threads creation and destruction is not incurred for each parallel region.
- Only three threads are created because the last parallel section will be invoked from the parent thread.
False Sharing
If independent data elements happen to sit on the same cache line, each update will cause the cache lines to “slosh back and forth” between threads. 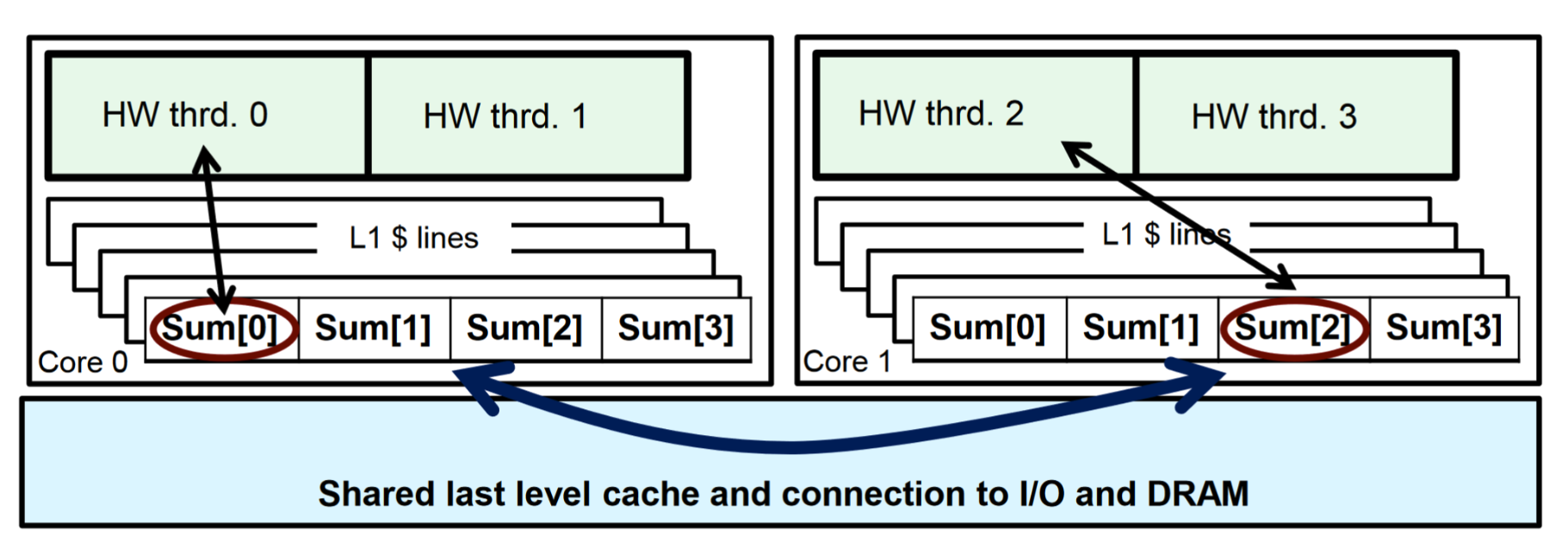
Hot fix: pad arrays so elements you use are on distinct cache lines.
SPMD vs WorkSharing
A parallel construct by itself creates an SPMD or “Single Program Multiple Data” program … i.e., each thread redundantly executes the same code.
- How do you split up pathways through the code between threads within a team?
- Work Sharing: The
OpenMPloop construct (not the only way to go)
- Work Sharing: The
- The loop work-sharing construct splits up loop iterations among the threads in a team
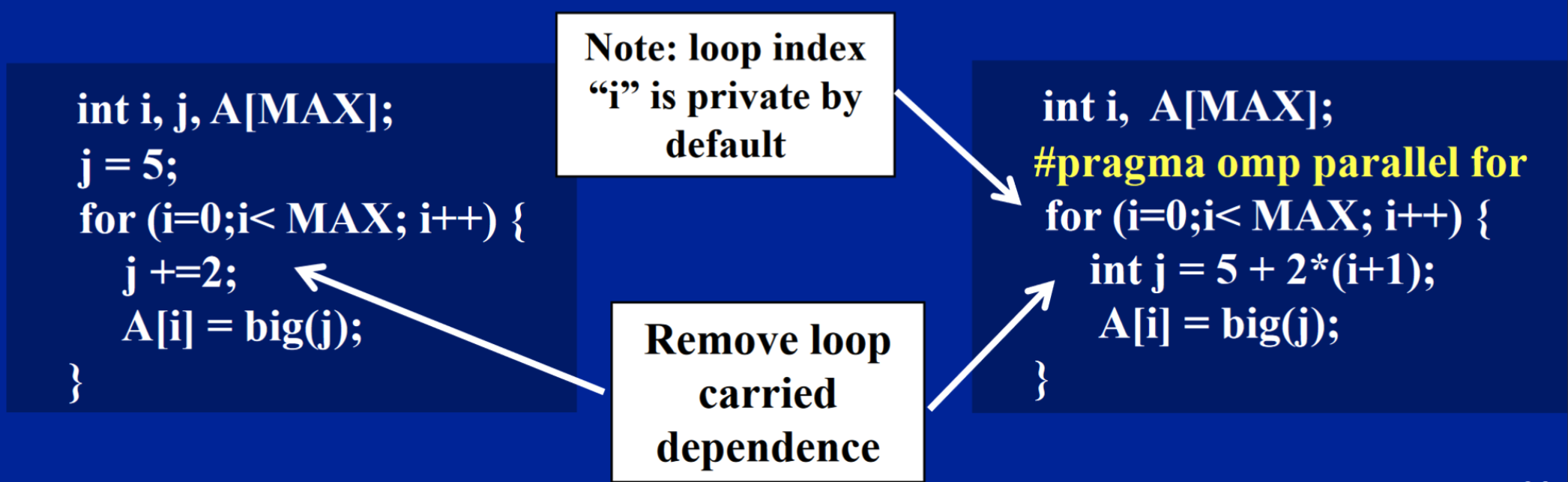
Working with Loops
{: .prompt-tip} >
- Find compute intensive loops
- Make the loop iterations independent
- So that they can safely execute in any order without loop-carried > dependencies
- Place the appropriate
OpenMPdirective and test
Reduction
OpenMP reduction clause:
reduction (op : list)
Inside a parallel or a work-sharing construct:
- A local copy of each list variable is made and initialized depending on the “
op” (e.g. 0 for “+”). - Updates occur on the local copy.
- Local copies are reduced into a single value and combined with the original global value.
The variables in “list” must be shared in the enclosing parallel region.
Example: PI with loop construct

OpenMP - Synchronization
Synchronization is used to impose order constraints and to protect access to shared data
High level synchronization:
- Critical, Atomic, Barrier, Ordered
Low level synchronization
- Flush, Locks (both simple and nested)
| Barrier | Each thread waits until all threads arrive. |
| Critical | Mutual exclusion: only one thread at a time can enter a critical region |
| Atomic | Mutual exclusion: only applies to the update of a memory location (the update of X in the following example) |
Locks in OpenMP
Simple Locks
- A simple lock is available if not set
- Routines:
omp_init_lock/omp_destroy_lock: create/destroy the lockomp_set_lock: acquire the lockomp_test_lock: test if the lock is available and set it if yes. Doesn’t block if already set.omp_unset_lock: release the lock
Nested Locks
- A nested lock is available if it is not set OR is set and the calling thread is equal to the current owner
- Same functions of the simple lock:
omp_*_nest_lock
Note: a lock implies a memory fence of all the thread variables
Scoped Locking VS OMP Critical
| Scoped Locking | OMP Critical |
|---|---|
| it is allowed to leave the locked region with jumps (e.g. break, continue, return), this is forbidden in regions protected by the critical-directive | no need to declare, initialize and destroy a lock |
| scoped locking is exception safe, critical is not | no need to include, declare and define a guard object yourself, as critical is a part of the language (OpenMP) |
| all criticals wait for each other, with guard objects you can have as many different locks as you like | you always have explicit control over where your critical section ends, where the end of the scoped lock is implicit |
| works for C and C++ (and FORTRAN) | |
| less overhead, as the compiler can translate it directly to lock and unlock calls, where it has to construct and destruct an object for scoped locking | |
Data sharing
The private directory doesn’t initialize the variables: 
Use firstprivate(number) to let OpenMP know to initialize private vars! 
Tasking
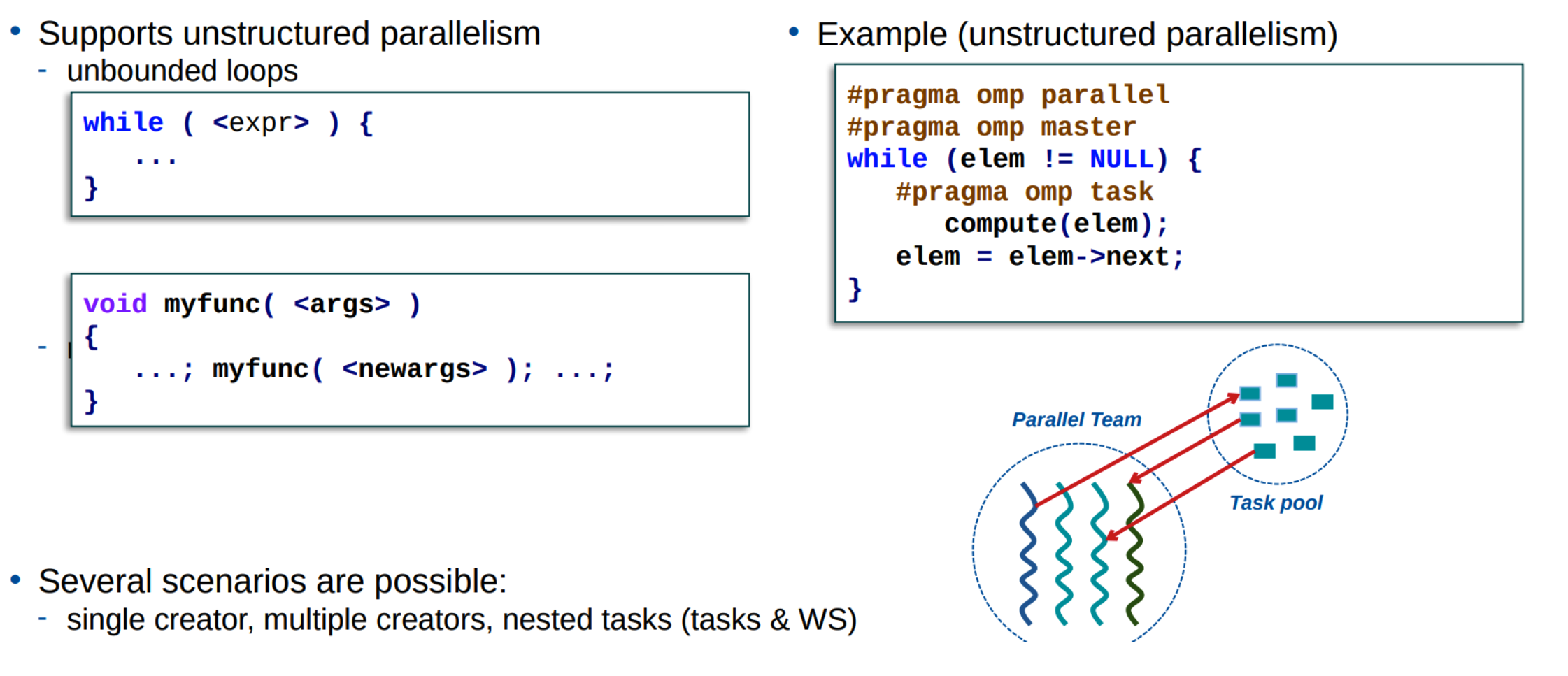
Task synchronization - Shallow
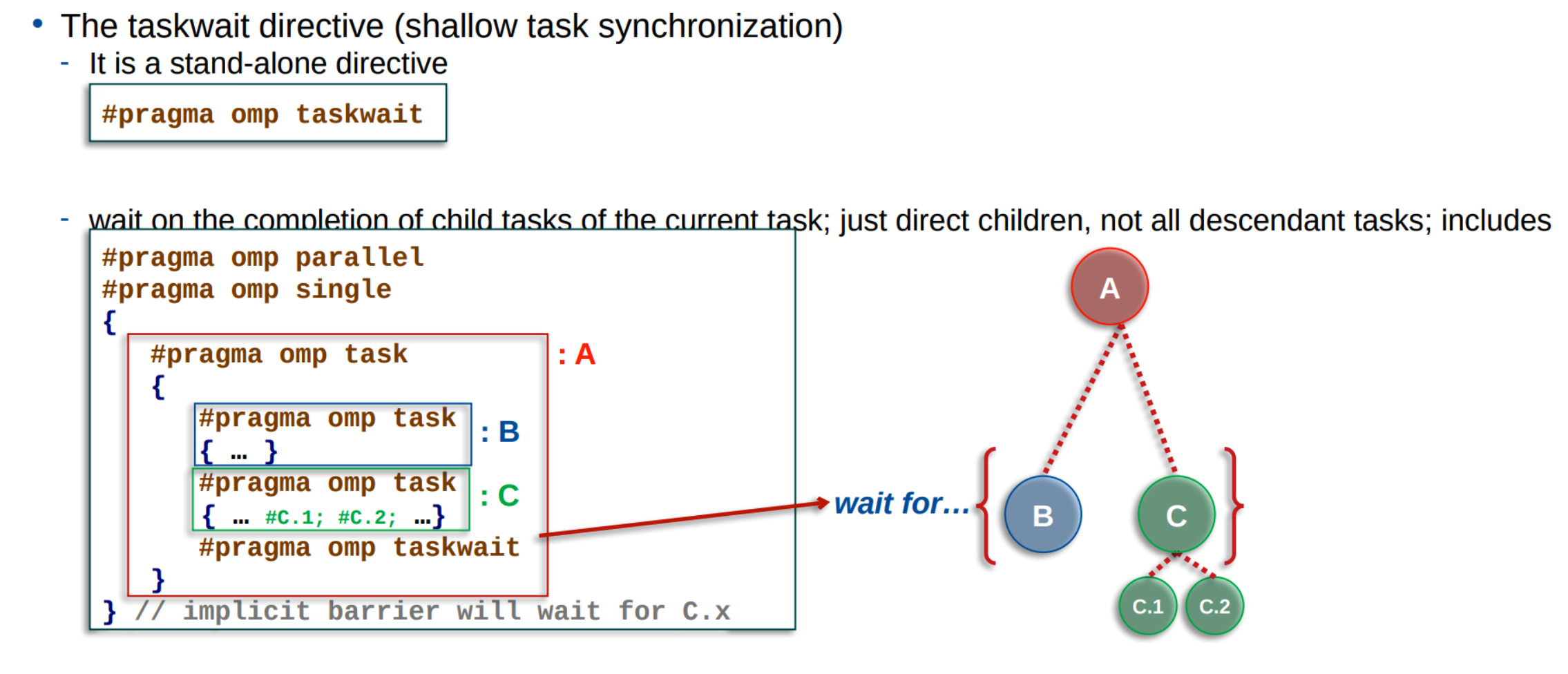
Task synchronization - Deep
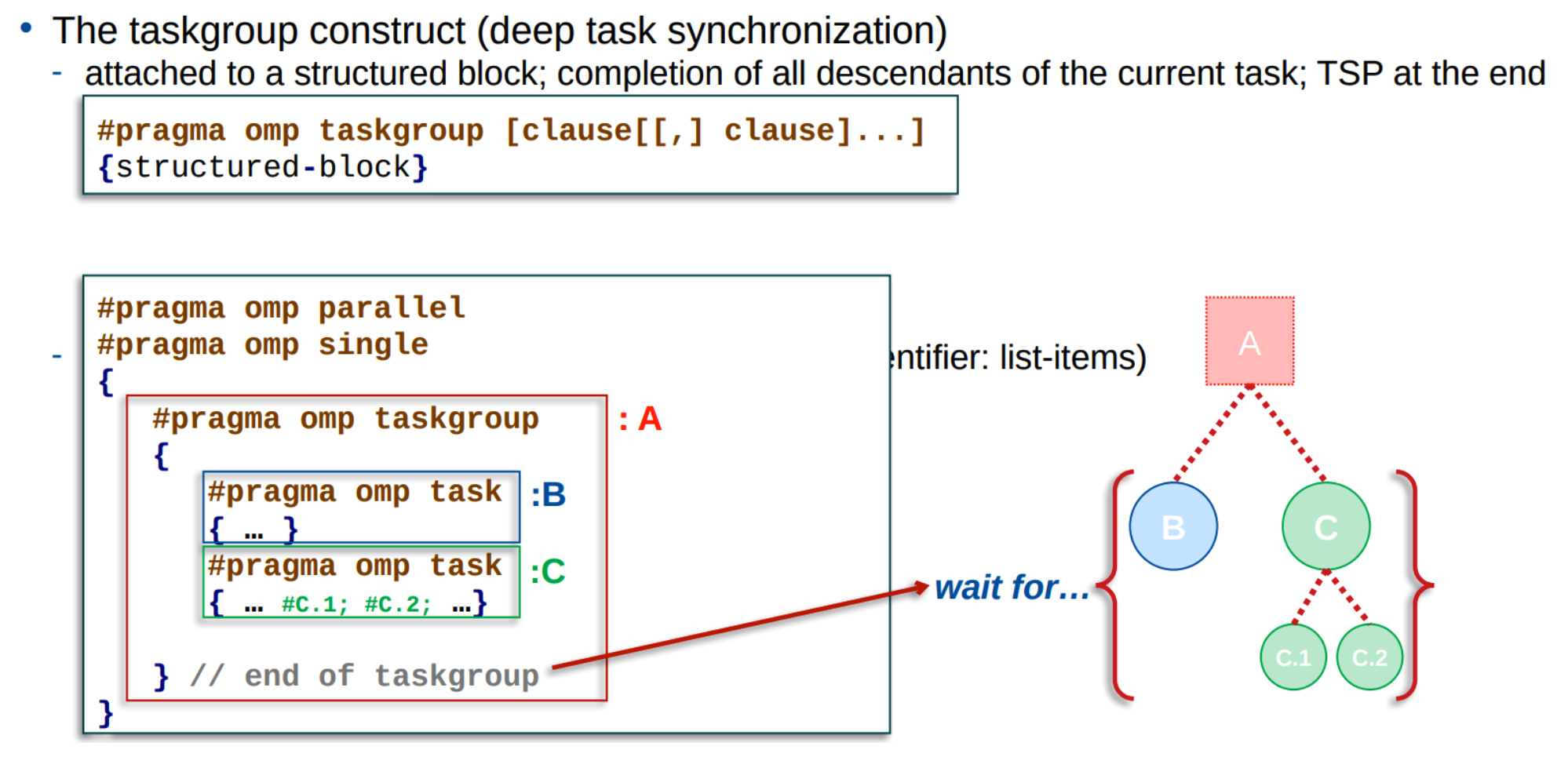
Dependencies between Tasks
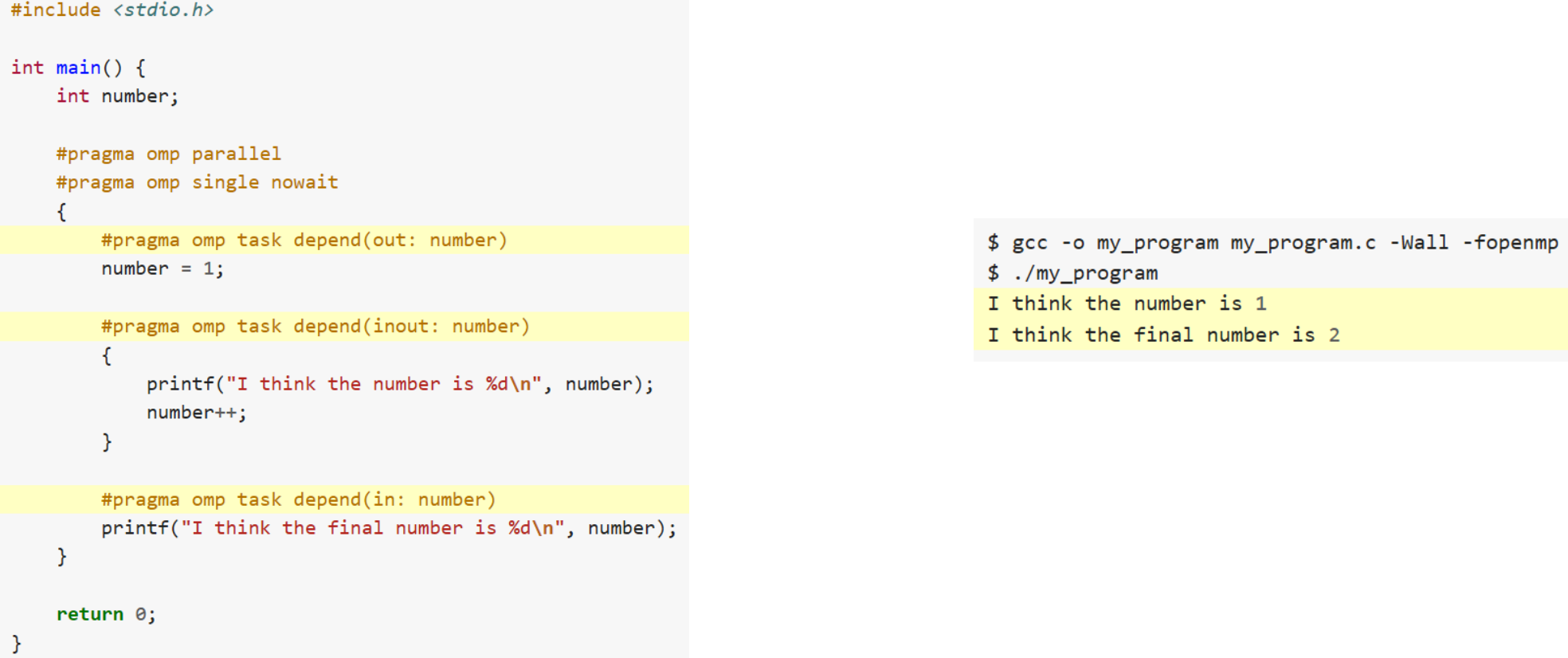
What will this program print? 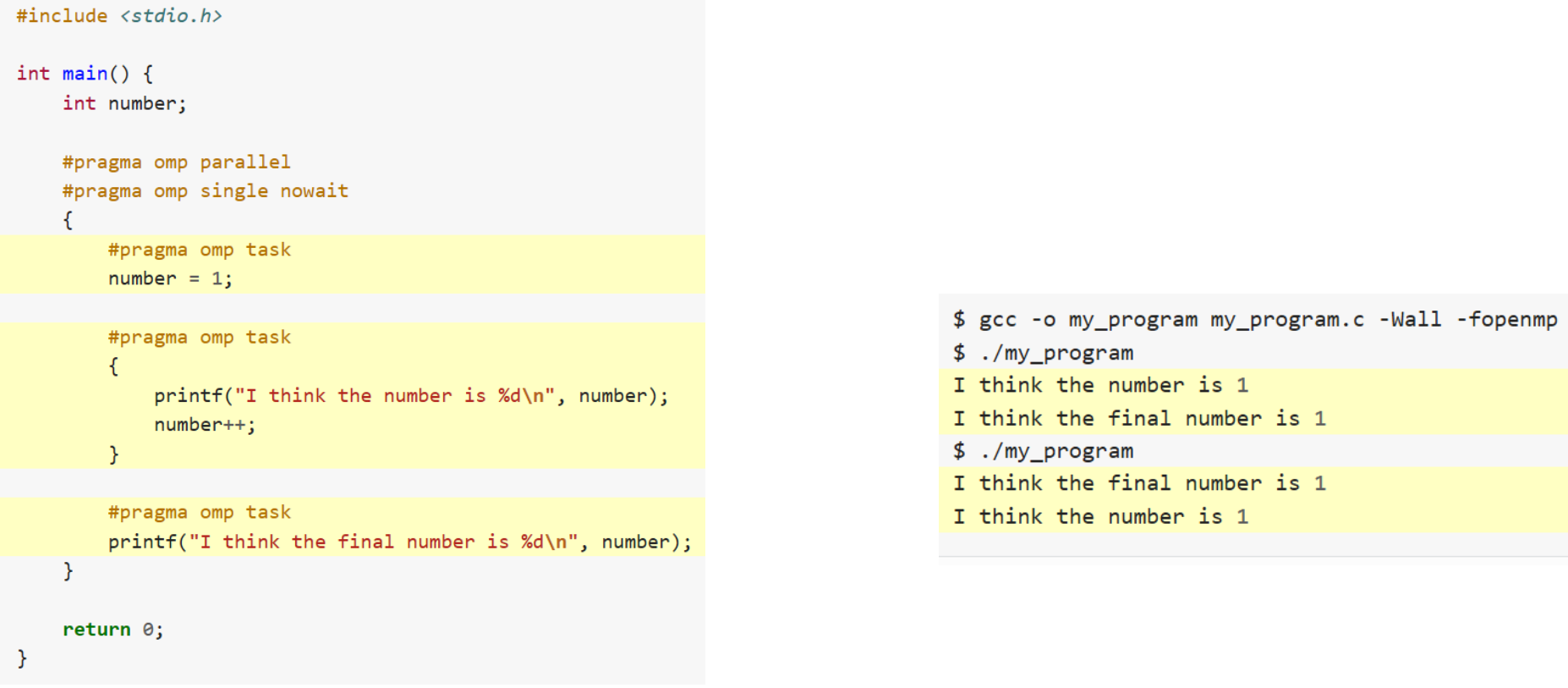
The depend clause
We can tell OpenMP which variables we are reading, writing or updating
- It allows us to implement arbitrary computational DAGs (!)